DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models In Cod…
페이지 정보
작성자 Flynn Kohn 작성일25-03-10 20:36 조회7회 댓글0건관련링크
본문
DeepSeek engineers say they achieved comparable outcomes with solely 2,000 GPUs. DeepSeek shortly gained attention with the discharge of its V3 model in late 2024. In a groundbreaking paper revealed in December, the company revealed it had educated the model using 2,000 Nvidia H800 chips at a price of under $6 million, a fraction of what its opponents usually spend. Install LiteLLM utilizing pip. A world retail firm boosted gross sales forecasting accuracy by 22% using DeepSeek V3. DeepSeek R1 has demonstrated competitive efficiency on various AI benchmarks, including a 79.8% accuracy on AIME 2024 and 97.3% on MATH-500. Auxiliary-Loss-Free Strategy: Ensures balanced load distribution without sacrificing performance. Unlike conventional fashions that rely on supervised high-quality-tuning (SFT), DeepSeek-R1 leverages pure RL training and hybrid methodologies to attain state-of-the-artwork efficiency in STEM tasks, coding, and advanced downside-fixing. On the core of DeepSeek’s groundbreaking know-how lies an innovative Mixture-of-Experts (MoE) architecture that essentially changes how AI models course of info.
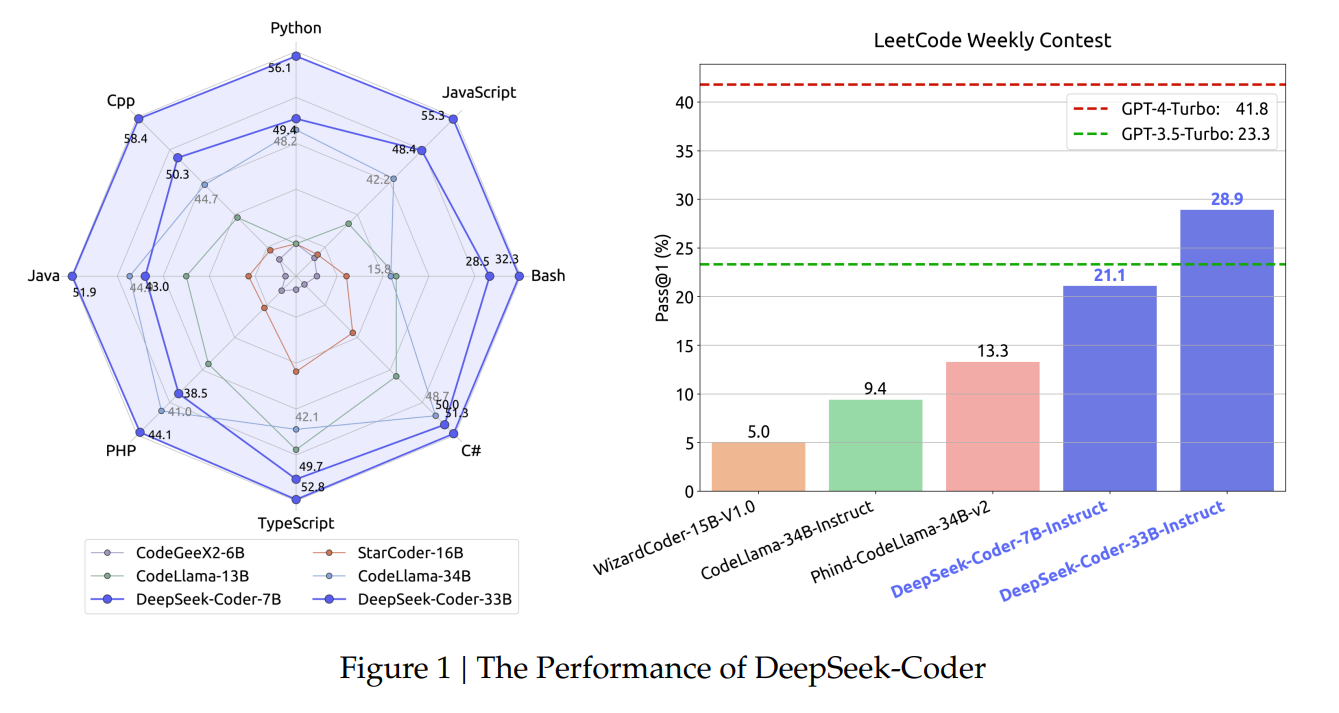
Its open-supply strategy and growing reputation counsel potential for continued enlargement, challenging established players in the sphere. In today’s quick-paced, knowledge-driven world, each businesses and individuals are looking out for innovative instruments that might help them faucet into the full potential of synthetic intelligence (AI). By delivering correct and timely insights, it allows users to make informed, information-pushed decisions. Hit 10 million customers in just 20 days (vs. 0.27 per million enter tokens (cache miss), and $1.10 per million output tokens. Transform your social media presence utilizing DeepSeek Video Generator. Chinese media outlet 36Kr estimates that the company has greater than 10,000 models in stock. In line with Forbes, DeepSeek used AMD Instinct GPUs (graphics processing items) and ROCM software at key levels of mannequin growth, particularly for DeepSeek-V3. DeepSeek may show that turning off entry to a key expertise doesn’t essentially imply the United States will win. The mannequin works fantastic in the terminal, however I can’t access the browser on this digital machine to use the Open WebUI. Among open models, we have seen CommandR, DBRX, Phi-3, Yi-1.5, Qwen2, DeepSeek v2, Mistral (NeMo, Large), Gemma 2, Llama 3, Nemotron-4. For example, the AMD Radeon RX 6850 XT (sixteen GB VRAM) has been used effectively to run LLaMA 3.2 11B with Ollama.
 In benchmark comparisons, Deepseek generates code 20% quicker than GPT-four and 35% faster than LLaMA 2, making it the go-to answer for fast improvement. Coding: Debugging complicated software, producing human-like code. It doesn’t just predict the subsequent word-it thoughtfully navigates complex challenges. The DeepSeek-R1, which was launched this month, focuses on complex duties equivalent to reasoning, coding, and maths. Utilize pre-constructed modules for coding, debugging, and testing. Realising the significance of this stock for AI training, Liang founded Deepseek Online chat and began utilizing them along with low-power chips to enhance his fashions. I installed the DeepSeek model on an Ubuntu Server 24.04 system without a GUI, on a digital machine using Hyper-V. Follow the directions to put in Docker on Ubuntu. For detailed steerage, please seek advice from the vLLM directions. Enter in a slicing-edge platform crafted to leverage AI’s energy and provide transformative options across various industries. API Integration: DeepSeek-R1’s APIs enable seamless integration with third-party functions, enabling companies to leverage its capabilities without overhauling their existing infrastructure.
In benchmark comparisons, Deepseek generates code 20% quicker than GPT-four and 35% faster than LLaMA 2, making it the go-to answer for fast improvement. Coding: Debugging complicated software, producing human-like code. It doesn’t just predict the subsequent word-it thoughtfully navigates complex challenges. The DeepSeek-R1, which was launched this month, focuses on complex duties equivalent to reasoning, coding, and maths. Utilize pre-constructed modules for coding, debugging, and testing. Realising the significance of this stock for AI training, Liang founded Deepseek Online chat and began utilizing them along with low-power chips to enhance his fashions. I installed the DeepSeek model on an Ubuntu Server 24.04 system without a GUI, on a digital machine using Hyper-V. Follow the directions to put in Docker on Ubuntu. For detailed steerage, please seek advice from the vLLM directions. Enter in a slicing-edge platform crafted to leverage AI’s energy and provide transformative options across various industries. API Integration: DeepSeek-R1’s APIs enable seamless integration with third-party functions, enabling companies to leverage its capabilities without overhauling their existing infrastructure.
댓글목록
등록된 댓글이 없습니다.