Have you Heard? Deepseek Is Your Best Bet To Grow
페이지 정보
작성자 Steve Loggins 작성일25-03-10 09:38 조회9회 댓글0건관련링크
본문
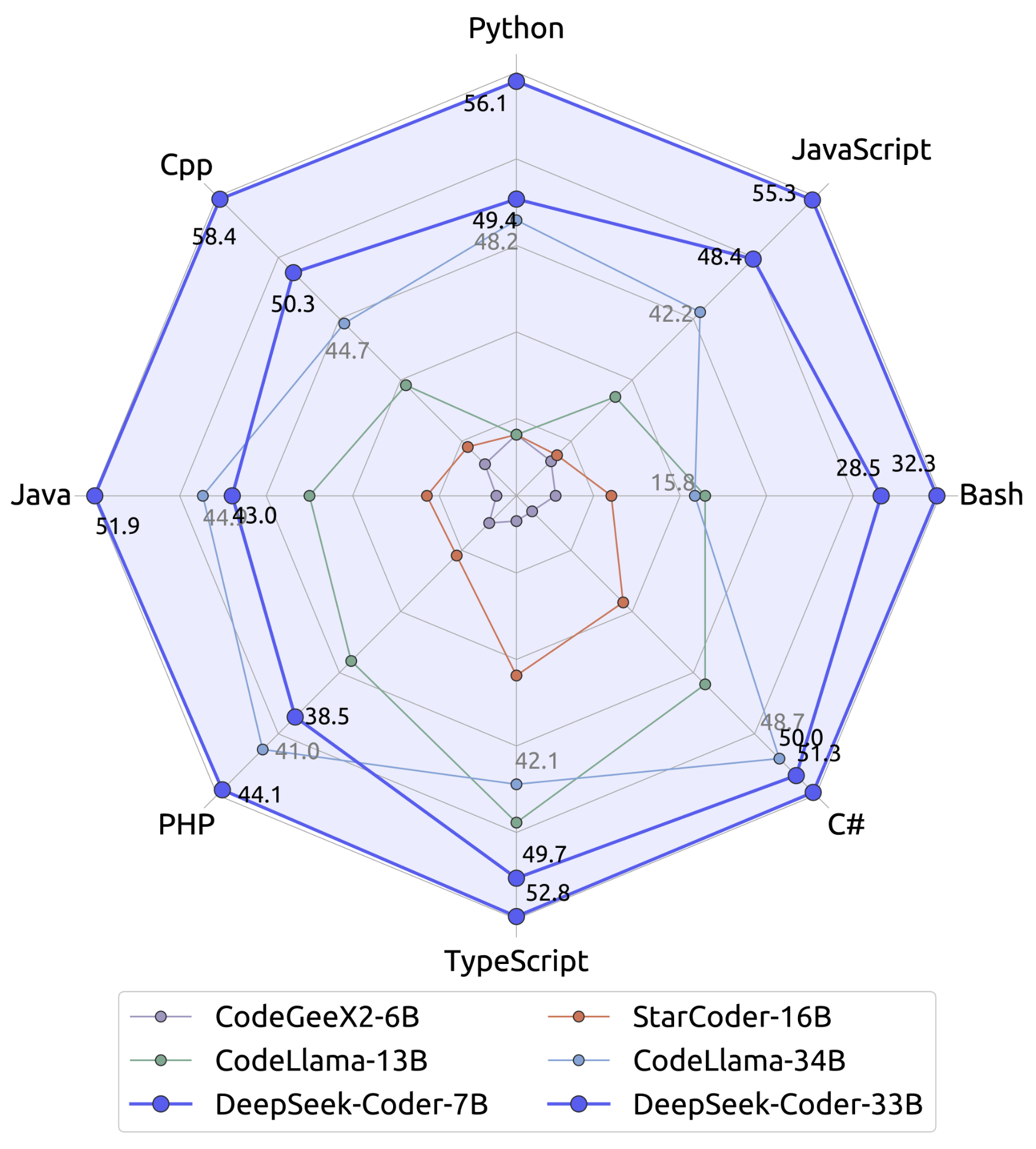
The Deepseek Online chat R1 model is "deepseek-ai/DeepSeek-R1". In line with Reuters, the DeepSeek-V3 mannequin has grow to be a top-rated free app on Apple’s App Store in the US. Therefore, DeepSeek-V3 doesn't drop any tokens throughout coaching. As for the coaching framework, we design the DualPipe algorithm for environment friendly pipeline parallelism, which has fewer pipeline bubbles and hides most of the communication during coaching by way of computation-communication overlap. On this framework, most compute-density operations are carried out in FP8, while a number of key operations are strategically maintained in their authentic information codecs to balance training effectivity and numerical stability. The model’s generalisation abilities are underscored by an distinctive score of sixty five on the challenging Hungarian National Highschool Exam. Here, we see a clear separation between Binoculars scores for human and AI-written code for all token lengths, with the anticipated result of the human-written code having a higher rating than the AI-written. Since launch, new approaches hit the leaderboards leading to a 12pp score increase to the 46% SOTA! Thus, we suggest that future chip designs increase accumulation precision in Tensor Cores to help full-precision accumulation, or select an applicable accumulation bit-width in keeping with the accuracy necessities of coaching and inference algorithms.
 128 parts, equivalent to four WGMMAs, represents the minimal accumulation interval that may significantly improve precision with out introducing substantial overhead. Since the MoE half solely must load the parameters of one professional, the reminiscence entry overhead is minimal, so using fewer SMs won't significantly have an effect on the general performance. Overall, underneath such a communication strategy, only 20 SMs are ample to fully utilize the bandwidths of IB and NVLink. There are rumors now of unusual things that happen to people. There is no reported connection between Ding’s alleged theft from Google and DeepSeek’s advancements, however solutions its new fashions could possibly be based mostly on expertise appropriated from American industry leaders swirled after the company’s announcement. The company’s disruptive affect on the AI business has led to vital market fluctuations, together with a notable decline in Nvidia‘s (NASDAQ: NVDA) stock value. On 27 Jan 2025, largely in response to the DeepSeek Chat-R1 rollout, Nvidia’s stock tumbled 17%, erasing billions of dollars (although it has subsequently recouped most of this loss). Economic Disruption: Lack of infrastructure, financial activity, and potential displacement of populations. Finally, we're exploring a dynamic redundancy strategy for consultants, where each GPU hosts extra experts (e.g., 16 experts), but only 9 will probably be activated during each inference step.
128 parts, equivalent to four WGMMAs, represents the minimal accumulation interval that may significantly improve precision with out introducing substantial overhead. Since the MoE half solely must load the parameters of one professional, the reminiscence entry overhead is minimal, so using fewer SMs won't significantly have an effect on the general performance. Overall, underneath such a communication strategy, only 20 SMs are ample to fully utilize the bandwidths of IB and NVLink. There are rumors now of unusual things that happen to people. There is no reported connection between Ding’s alleged theft from Google and DeepSeek’s advancements, however solutions its new fashions could possibly be based mostly on expertise appropriated from American industry leaders swirled after the company’s announcement. The company’s disruptive affect on the AI business has led to vital market fluctuations, together with a notable decline in Nvidia‘s (NASDAQ: NVDA) stock value. On 27 Jan 2025, largely in response to the DeepSeek Chat-R1 rollout, Nvidia’s stock tumbled 17%, erasing billions of dollars (although it has subsequently recouped most of this loss). Economic Disruption: Lack of infrastructure, financial activity, and potential displacement of populations. Finally, we're exploring a dynamic redundancy strategy for consultants, where each GPU hosts extra experts (e.g., 16 experts), but only 9 will probably be activated during each inference step.
 Also, our information processing pipeline is refined to attenuate redundancy whereas maintaining corpus diversity. This strategy ensures that errors stay inside acceptable bounds while maintaining computational effectivity. The pretokenizer and training knowledge for our tokenizer are modified to optimize multilingual compression effectivity. For MoE fashions, an unbalanced expert load will result in routing collapse (Shazeer et al., 2017) and diminish computational effectivity in scenarios with knowledgeable parallelism. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the hassle to ensure load stability. These options along with basing on profitable DeepSeekMoE structure lead to the next leads to implementation. Figure 2 illustrates the essential structure of DeepSeek-V3, and we are going to briefly review the main points of MLA and DeepSeekMoE in this part. Notable innovations: DeepSeek-V2 ships with a notable innovation referred to as MLA (Multi-head Latent Attention). The eye part employs 4-manner Tensor Parallelism (TP4) with Sequence Parallelism (SP), mixed with 8-method Data Parallelism (DP8). Although DeepSeek released the weights, the training code isn't accessible and the corporate did not launch much info concerning the training data. To additional guarantee numerical stability, we store the master weights, weight gradients, and optimizer states in increased precision.
Also, our information processing pipeline is refined to attenuate redundancy whereas maintaining corpus diversity. This strategy ensures that errors stay inside acceptable bounds while maintaining computational effectivity. The pretokenizer and training knowledge for our tokenizer are modified to optimize multilingual compression effectivity. For MoE fashions, an unbalanced expert load will result in routing collapse (Shazeer et al., 2017) and diminish computational effectivity in scenarios with knowledgeable parallelism. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the hassle to ensure load stability. These options along with basing on profitable DeepSeekMoE structure lead to the next leads to implementation. Figure 2 illustrates the essential structure of DeepSeek-V3, and we are going to briefly review the main points of MLA and DeepSeekMoE in this part. Notable innovations: DeepSeek-V2 ships with a notable innovation referred to as MLA (Multi-head Latent Attention). The eye part employs 4-manner Tensor Parallelism (TP4) with Sequence Parallelism (SP), mixed with 8-method Data Parallelism (DP8). Although DeepSeek released the weights, the training code isn't accessible and the corporate did not launch much info concerning the training data. To additional guarantee numerical stability, we store the master weights, weight gradients, and optimizer states in increased precision.
Based on our mixed precision FP8 framework, we introduce several strategies to reinforce low-precision training accuracy, focusing on each the quantization method and the multiplication course of. Along side our FP8 coaching framework, we additional reduce the memory consumption and communication overhead by compressing cached activations and optimizer states into decrease-precision codecs. Moreover, to further reduce memory and communication overhead in MoE training, we cache and dispatch activations in FP8, while storing low-precision optimizer states in BF16. However, this requires extra cautious optimization of the algorithm that computes the globally optimal routing scheme and the fusion with the dispatch kernel to reduce overhead. All-to-all communication of the dispatch and combine elements is performed by way of direct level-to-point transfers over IB to realize low latency. For the MoE all-to-all communication, we use the identical methodology as in coaching: first transferring tokens across nodes by way of IB, after which forwarding among the many intra-node GPUs via NVLink. In this overlapping technique, we are able to be certain that both all-to-all and PP communication will be absolutely hidden throughout execution. Given the environment friendly overlapping strategy, the full DualPipe scheduling is illustrated in Figure 5. It employs a bidirectional pipeline scheduling, which feeds micro-batches from each ends of the pipeline simultaneously and a big portion of communications might be totally overlapped.
If you enjoyed this article and you would certainly like to get even more details relating to free Deep seek kindly see the site.
댓글목록
등록된 댓글이 없습니다.