What $325 Buys You In Deepseek Chatgpt
페이지 정보
작성자 Lashunda 작성일25-03-04 14:28 조회12회 댓글0건관련링크
본문
 For instance, OpenAI's GPT-3.5, which was released in 2023, was trained on roughly 570GB of textual content data from the repository Common Crawl - which amounts to roughly 300 billion words - taken from books, online articles, Wikipedia and different webpages. Following scorching on its heels is an even newer mannequin referred to as DeepSeek-R1, released Monday (Jan. 20). In third-party benchmark assessments, DeepSeek-V3 matched the capabilities of OpenAI's GPT-4o and Anthropic's Claude Sonnet 3.5 whereas outperforming others, comparable to Meta's Llama 3.1 and Alibaba's Qwen2.5, in duties that included drawback-solving, coding and math. DeepSeek-R1, a brand new reasoning mannequin made by Chinese researchers, completes duties with a comparable proficiency to OpenAI's o1 at a fraction of the associated fee. While media reports present much less clarity on DeepSeek, the newly released model, DeepSeek-R1, appeared to rival OpenAI's o1 on several performance benchmarks. China has released a cheap, open-source rival to OpenAI's ChatGPT, and it has some scientists excited and Silicon Valley fearful. It took a highly constrained staff from China to remind us all of those fundamental lessons of computing historical past. China’s value-effective and Free DeepSeek (hedgedoc.digillab.uni-augsburg.de) synthetic intelligence (AI) chatbot took the world by storm resulting from its fast progress rivaling the US-based OpenAI’s ChatGPT with far fewer sources out there.
For instance, OpenAI's GPT-3.5, which was released in 2023, was trained on roughly 570GB of textual content data from the repository Common Crawl - which amounts to roughly 300 billion words - taken from books, online articles, Wikipedia and different webpages. Following scorching on its heels is an even newer mannequin referred to as DeepSeek-R1, released Monday (Jan. 20). In third-party benchmark assessments, DeepSeek-V3 matched the capabilities of OpenAI's GPT-4o and Anthropic's Claude Sonnet 3.5 whereas outperforming others, comparable to Meta's Llama 3.1 and Alibaba's Qwen2.5, in duties that included drawback-solving, coding and math. DeepSeek-R1, a brand new reasoning mannequin made by Chinese researchers, completes duties with a comparable proficiency to OpenAI's o1 at a fraction of the associated fee. While media reports present much less clarity on DeepSeek, the newly released model, DeepSeek-R1, appeared to rival OpenAI's o1 on several performance benchmarks. China has released a cheap, open-source rival to OpenAI's ChatGPT, and it has some scientists excited and Silicon Valley fearful. It took a highly constrained staff from China to remind us all of those fundamental lessons of computing historical past. China’s value-effective and Free DeepSeek (hedgedoc.digillab.uni-augsburg.de) synthetic intelligence (AI) chatbot took the world by storm resulting from its fast progress rivaling the US-based OpenAI’s ChatGPT with far fewer sources out there.
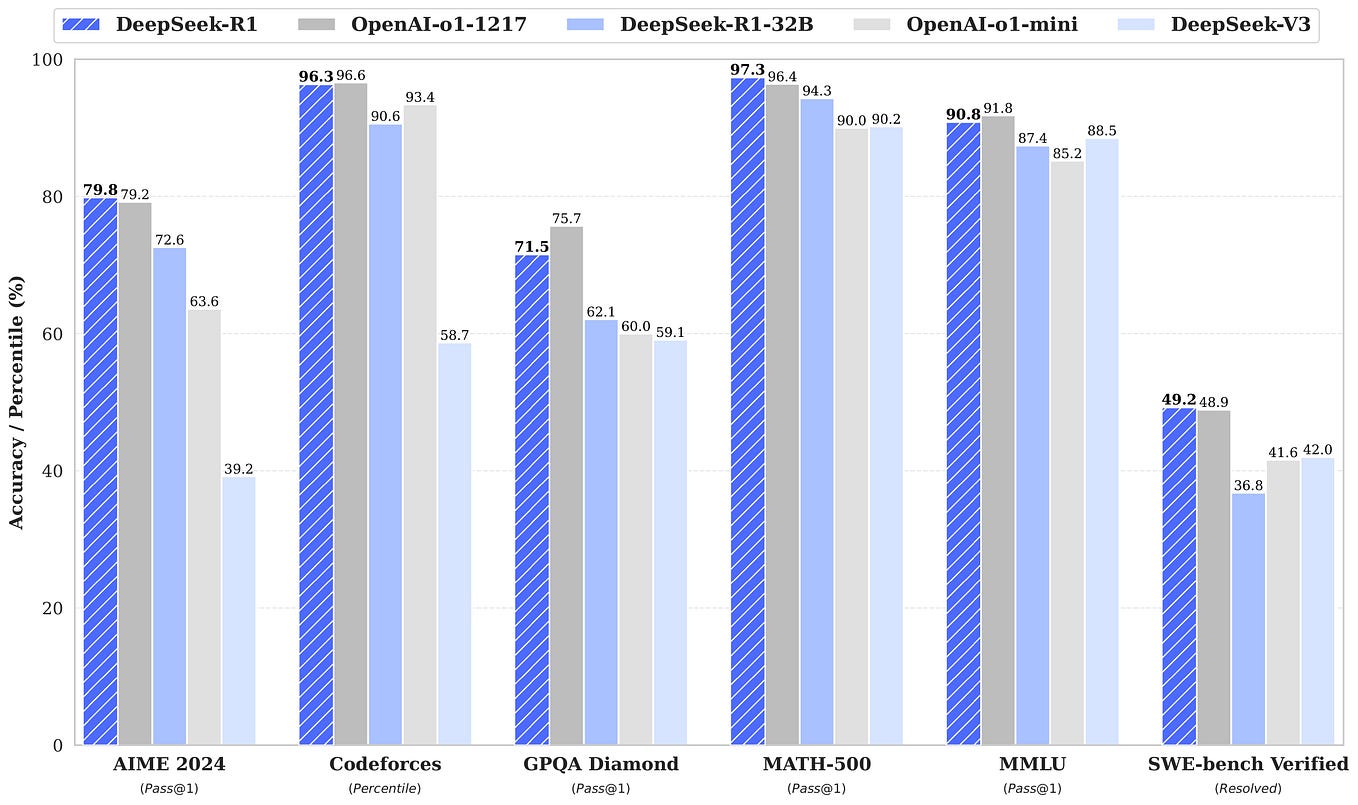 OpenAI has reportedly spent over $a hundred million for essentially the most superior model of ChatGPT, the o1, which DeepSeek is rivaling and surpassing in certain benchmarks. The world’s leading AI corporations use over 16,000 chips to train their fashions, while DeepSeek only used 2,000 chips which are older, with a less than $6 million budget. LitCab: Lightweight Language Model Calibration over Short- and Long-form Responses. High Flyer, the hedge fund that backs DeepSeek, stated that the model almost matches the efficiency of LLMs constructed by U.S. As well as, U.S. export controls, which limit Chinese companies' access to the most effective AI computing chips, pressured R1's developers to build smarter, more power-efficient algorithms to compensate for their lack of computing power. If indeed the long run AI trend is towards inference, then Chinese AI firms could compete on a extra even playing field. The rapid progress of the massive language mannequin (LLM) gained heart stage within the tech world, as it isn't only Free Deepseek Online chat, open-supply, and extra efficient to run, but it was additionally developed and skilled utilizing older-technology chips because of the US’ chip restrictions on China. The Singapore case is part of a complete probe into illicit AI chip movements, involving 22 entities on suspicion of misleading actions.
OpenAI has reportedly spent over $a hundred million for essentially the most superior model of ChatGPT, the o1, which DeepSeek is rivaling and surpassing in certain benchmarks. The world’s leading AI corporations use over 16,000 chips to train their fashions, while DeepSeek only used 2,000 chips which are older, with a less than $6 million budget. LitCab: Lightweight Language Model Calibration over Short- and Long-form Responses. High Flyer, the hedge fund that backs DeepSeek, stated that the model almost matches the efficiency of LLMs constructed by U.S. As well as, U.S. export controls, which limit Chinese companies' access to the most effective AI computing chips, pressured R1's developers to build smarter, more power-efficient algorithms to compensate for their lack of computing power. If indeed the long run AI trend is towards inference, then Chinese AI firms could compete on a extra even playing field. The rapid progress of the massive language mannequin (LLM) gained heart stage within the tech world, as it isn't only Free Deepseek Online chat, open-supply, and extra efficient to run, but it was additionally developed and skilled utilizing older-technology chips because of the US’ chip restrictions on China. The Singapore case is part of a complete probe into illicit AI chip movements, involving 22 entities on suspicion of misleading actions.
Live Science is a part of Future US Inc, a global media group and main digital writer.
댓글목록
등록된 댓글이 없습니다.