How one can Something Your Deepseek China Ai
페이지 정보
작성자 Monte Butters 작성일25-03-03 21:15 조회12회 댓글0건관련링크
본문
However, having to work with another crew or firm to obtain your compute resources additionally provides each technical and coordination prices, because every cloud works a bit of in a different way. On rare occasions, our expert staff of analysts issues a "Double Down" stock suggestion for companies that they think are about to pop. Well, not quite. The increased use of renewable power and the innovations in energy efficiency are key. Thus, the effectivity of your parallel processing determines how effectively you may maximize the compute energy of your GPU cluster. These ultimate two charts are merely for instance that the present results is probably not indicative of what we are able to count on sooner or later. There are two networking products in a Nvidia GPU cluster - NVLink, which connects every GPU chip to each other inside a node, and Infiniband, which connects every node to the opposite inside an information center. If you combine the first two idiosyncratic advantages - no enterprise model plus running your individual datacenter - you get the third: a excessive level of software optimization expertise on limited hardware assets. Considered one of DeepSeek’s idiosyncratic advantages is that the team runs its personal knowledge centers. To be clear, having a hyperscaler’s infrastructural backing has many advantages.
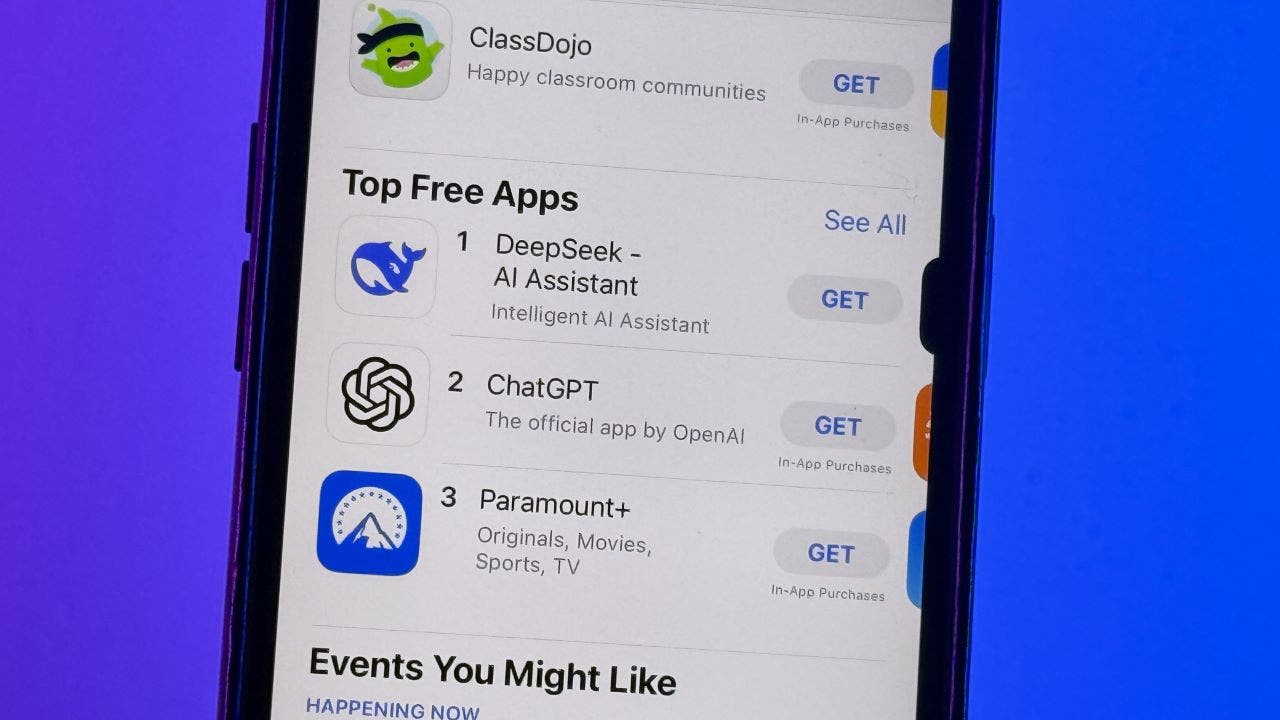 Despite having restricted GPU resources due to export management and smaller budget in comparison with other tech giants, there isn't any inner coordination, bureaucracy, or politics to navigate to get compute sources. With NVLink having greater bandwidth than Infiniband, it is not hard to think about that in a fancy training setting of hundreds of billions of parameters (DeepSeek-V3 has 671 billion whole parameters), with partial solutions being handed round between thousands of GPUs, the community can get fairly congested whereas the whole training course of slows down. Introducing ChatGPT search. ChatGPT now affords an improved internet search functionality, offering quick, current solutions with links to related sources - solutions you’d usually Deep seek via a search engine. By Monday, DeepSeek’s AI assistant had rapidly overtaken ChatGPT as the most well-liked free app in Apple’s US and UK app shops. Just every week after launching its R1 synthetic intelligence mannequin, DeepSeek took the title for many downloaded free app within the United States. DeepSeek's AI Assistanthas overtaken rival ChatGPT to become the highest-rated free app on Apple's App Store in the US. While chatbots including OpenAI’s ChatGPT usually are not yet powerful enough to straight produce full quant strategies, corporations resembling Longqi have additionally been using them to accelerate analysis.
Despite having restricted GPU resources due to export management and smaller budget in comparison with other tech giants, there isn't any inner coordination, bureaucracy, or politics to navigate to get compute sources. With NVLink having greater bandwidth than Infiniband, it is not hard to think about that in a fancy training setting of hundreds of billions of parameters (DeepSeek-V3 has 671 billion whole parameters), with partial solutions being handed round between thousands of GPUs, the community can get fairly congested whereas the whole training course of slows down. Introducing ChatGPT search. ChatGPT now affords an improved internet search functionality, offering quick, current solutions with links to related sources - solutions you’d usually Deep seek via a search engine. By Monday, DeepSeek’s AI assistant had rapidly overtaken ChatGPT as the most well-liked free app in Apple’s US and UK app shops. Just every week after launching its R1 synthetic intelligence mannequin, DeepSeek took the title for many downloaded free app within the United States. DeepSeek's AI Assistanthas overtaken rival ChatGPT to become the highest-rated free app on Apple's App Store in the US. While chatbots including OpenAI’s ChatGPT usually are not yet powerful enough to straight produce full quant strategies, corporations resembling Longqi have additionally been using them to accelerate analysis.
But some observers are skeptical that the vendor carried out inferencing and coaching of its model as cheaply because the startup -- which originated as a hedge fund firm -- claims, Chandrasekaran mentioned. To extend coaching effectivity, this framework included a new and improved parallel processing algorithm, DualPipe. At the guts of coaching any large AI fashions is parallel processing, the place each accelerator chip calculates a partial reply to all the complicated mathematical equations earlier than aggregating all the elements into the final answer. To scale back networking congestion and get the most out of the treasured few H800s it possesses, Deepseek Online chat online designed its personal load-balancing communications kernel to optimize the bandwidth differences between NVLink and Infiniband to maximize cross-node all-to-all communications between the GPUs, so every chip is all the time solving some type of partial reply and never have to wait round for one thing to do. Meanwhile, if you end up useful resource constrained, or "GPU poor", thus must squeeze every drop of performance out of what you will have, realizing exactly how your infra is constructed and operated can provide you with a leg up in realizing the place and the best way to optimize. Since we all know that DeepSeek used 2048 H800s, there are possible 256 nodes of 8-GPU servers, connected by Infiniband.
Not needing to manage your individual infrastructure and just assuming that the GPUs will probably be there frees up the R&D team to do what they're good at, which isn't managing infrastructure. By far probably the most fascinating part (no less than to a cloud infra nerd like me) is the "Infractructures" part, where the Deepseek Online chat crew defined intimately the way it managed to reduce the cost of coaching at the framework, information format, and networking level. Its group and setup - no enterprise mannequin, personal datacenter, software program-to-hardware experience - resemble extra of an educational research lab that has a sizable compute capability, but no grant writing or journal publishing pressure with a sizable price range, than its peers within the fiercely competitive AI trade. Think variety of decimal locations as an analogy, FP32 has more decimals than FP8, thus extra numbers to retailer in memory. FP8 is a much less exact data format than FP16 or FP32.
댓글목록
등록된 댓글이 없습니다.