Eight Undeniable Facts About Deepseek
페이지 정보
작성자 Leigh Vonwiller 작성일25-03-03 14:05 조회11회 댓글0건관련링크
본문
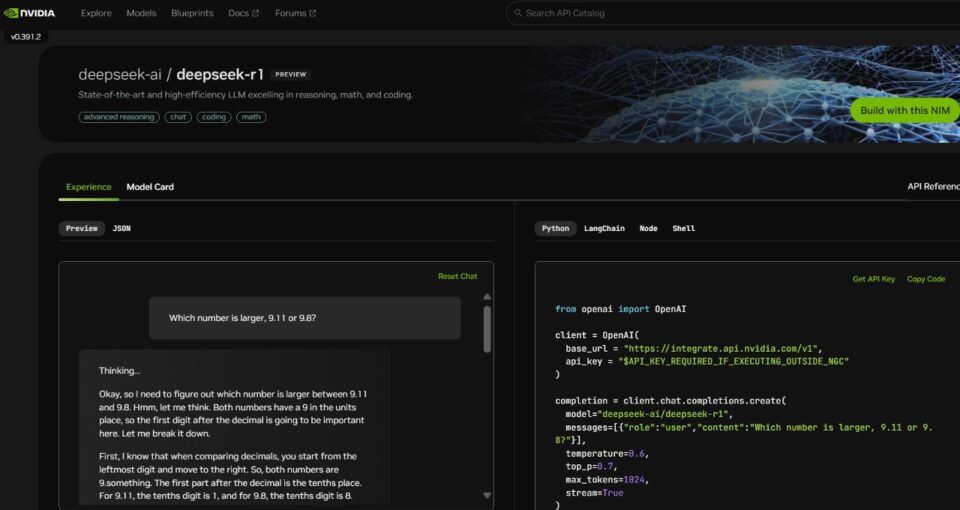 The DeepSeek mobile app does some actually foolish things, like plain-text HTTP for the registration sequence. Specifically, users can leverage DeepSeek’s AI model through self-hosting, hosted versions from corporations like Microsoft, or just leverage a distinct AI capability. The December 2024 controls change that by adopting for the primary time nation-extensive restrictions on the export of advanced HBM to China in addition to an end-use and end-consumer controls on the sale of even much less superior variations of HBM. Luo et al. (2024) Y. Luo, Z. Zhang, DeepSeek R. Wu, H. Liu, Y. Jin, K. Zheng, M. Wang, Z. He, G. Hu, L. Chen, et al. On Codeforces, OpenAI o1-1217 leads with 96.6%, whereas DeepSeek-R1 achieves 96.3%. This benchmark evaluates coding and algorithmic reasoning capabilities. Not necessarily. ChatGPT made OpenAI the unintended consumer tech company, which is to say a product company; there's a route to building a sustainable shopper business on commoditizable models by some mixture of subscriptions and advertisements. In keeping with a new Ipsos poll, China is essentially the most optimistic about AI’s skill to create jobs out of the 33 nations surveyed, up there with Indonesia, Thailand, Turkey, Malaysia and India.
The DeepSeek mobile app does some actually foolish things, like plain-text HTTP for the registration sequence. Specifically, users can leverage DeepSeek’s AI model through self-hosting, hosted versions from corporations like Microsoft, or just leverage a distinct AI capability. The December 2024 controls change that by adopting for the primary time nation-extensive restrictions on the export of advanced HBM to China in addition to an end-use and end-consumer controls on the sale of even much less superior variations of HBM. Luo et al. (2024) Y. Luo, Z. Zhang, DeepSeek R. Wu, H. Liu, Y. Jin, K. Zheng, M. Wang, Z. He, G. Hu, L. Chen, et al. On Codeforces, OpenAI o1-1217 leads with 96.6%, whereas DeepSeek-R1 achieves 96.3%. This benchmark evaluates coding and algorithmic reasoning capabilities. Not necessarily. ChatGPT made OpenAI the unintended consumer tech company, which is to say a product company; there's a route to building a sustainable shopper business on commoditizable models by some mixture of subscriptions and advertisements. In keeping with a new Ipsos poll, China is essentially the most optimistic about AI’s skill to create jobs out of the 33 nations surveyed, up there with Indonesia, Thailand, Turkey, Malaysia and India.
 While the industry’s attention was mounted on proprietary advancements, DeepSeek made a robust assertion about the function of open-supply innovation in AI’s future. Unlike traditional LLMs that depend on Transformer architectures which requires reminiscence-intensive caches for storing raw key-value (KV), DeepSeek-V3 employs an revolutionary Multi-Head Latent Attention (MHLA) mechanism. While efficient, this method requires immense hardware assets, driving up costs and making scalability impractical for many organizations. This strategy ensures that computational assets are allotted strategically the place wanted, reaching excessive performance with out the hardware calls for of conventional fashions. MHLA transforms how KV caches are managed by compressing them into a dynamic latent area using "latent slots." These slots function compact reminiscence models, distilling solely the most critical data while discarding pointless particulars. The ability to suppose via options and search a bigger possibility space and backtrack the place wanted to retry. This platform offers a number of advanced models, including conversational AI for chatbots, actual-time search features, and textual content era fashions. Will this end in next technology models that are autonomous like cats or completely purposeful like Data? AI models like DeepSeek are enabling new functions, from improving customer service effectivity to providing real-time sentiment evaluation at a fraction of the cost of older models.
While the industry’s attention was mounted on proprietary advancements, DeepSeek made a robust assertion about the function of open-supply innovation in AI’s future. Unlike traditional LLMs that depend on Transformer architectures which requires reminiscence-intensive caches for storing raw key-value (KV), DeepSeek-V3 employs an revolutionary Multi-Head Latent Attention (MHLA) mechanism. While efficient, this method requires immense hardware assets, driving up costs and making scalability impractical for many organizations. This strategy ensures that computational assets are allotted strategically the place wanted, reaching excessive performance with out the hardware calls for of conventional fashions. MHLA transforms how KV caches are managed by compressing them into a dynamic latent area using "latent slots." These slots function compact reminiscence models, distilling solely the most critical data while discarding pointless particulars. The ability to suppose via options and search a bigger possibility space and backtrack the place wanted to retry. This platform offers a number of advanced models, including conversational AI for chatbots, actual-time search features, and textual content era fashions. Will this end in next technology models that are autonomous like cats or completely purposeful like Data? AI models like DeepSeek are enabling new functions, from improving customer service effectivity to providing real-time sentiment evaluation at a fraction of the cost of older models.
US-based corporations like OpenAI, Anthropic, and Meta have dominated the sphere for years. With its newest model, DeepSeek-V3, Deepseek AI Online chat the corporate is just not only rivalling established tech giants like OpenAI’s GPT-4o, Anthropic’s Claude 3.5, and Meta’s Llama 3.1 in performance but additionally surpassing them in value-efficiency. DeepSeek's PCIe A100 architecture demonstrates significant value control and performance advantages over the NVIDIA DGX-A100 structure. We have now these models which might management computer systems now, write code, and surf the online, which suggests they'll work together with something that is digital, assuming there’s a very good interface. Together, what all this implies is that we're nowhere close to AI itself hitting a wall. What this implies is that if you'd like to connect your biology lab to a big language model, that's now extra possible. Because the demand for advanced large language models (LLMs) grows, so do the challenges related to their deployment. "Despite their obvious simplicity, these problems typically involve complex solution techniques, making them excellent candidates for constructing proof information to enhance theorem-proving capabilities in Large Language Models (LLMs)," the researchers write. And this isn't even mentioning the work inside Deepmind of making the Alpha model collection and attempting to include those into the massive Language world.
It can be easy to forget that these fashions be taught concerning the world seeing nothing but tokens, vectors that symbolize fractions of a world they've by no means truly seen or skilled. He was not too long ago seen at a gathering hosted by China's premier Li Qiang, reflecting DeepSeek's growing prominence within the AI business. The timing of the attack coincided with DeepSeek's AI assistant app overtaking ChatGPT as the top downloaded app on the Apple App Store. This repo accommodates GPTQ model files for Free DeepSeek online's Deepseek Coder 33B Instruct. Large-scale mannequin training often faces inefficiencies attributable to GPU communication overhead. DeepEP enhances GPU communication by providing high throughput and low-latency interconnectivity, significantly improving the effectivity of distributed coaching and inference. DeepSeek-V3 addresses these limitations by means of modern design and engineering decisions, successfully dealing with this trade-off between efficiency, scalability, and excessive performance. Existing LLMs make the most of the transformer structure as their foundational model design. Unlike conventional fashions, DeepSeek-V3 employs a Mixture-of-Experts (MoE) structure that selectively activates 37 billion parameters per token.
For more in regards to topics stop by the web-site.
댓글목록
등록된 댓글이 없습니다.