The Birth Of Deepseek
페이지 정보
작성자 Chadwick 작성일25-03-02 16:00 조회4회 댓글0건관련링크
본문
DeepSeek did not invent the strategy, but its use roiled the markets and woke the AI world up to its potential. Challenge: Hyper-correct forecasting is important for staying ahead in competitive markets. Such steps would complicate the company’s potential to gain widespread adoption within the US and allied markets. Depending on how much VRAM you've got on your machine, you might have the ability to take advantage of Ollama’s capacity to run multiple models and handle multiple concurrent requests through the use of DeepSeek Coder 6.7B for autocomplete and Llama 3 8B for chat. Angular's team have a nice method, where they use Vite for growth due to velocity, and for manufacturing they use esbuild. Ease of Use - Simple and intuitive for day-to-day questions and interactions. Join the WasmEdge discord to ask questions and share insights. Interestingly, DeepSeek appears to have turned these limitations into an advantage. There are two key limitations of the H800s DeepSeek had to make use of compared to H100s.
 It will be fascinating to track the trade-offs as more people use it in numerous contexts. 5.2 Without our permission, you or your end customers shall not use any trademarks, service marks, commerce names, domain names, web site names, firm logos (LOGOs), URLs, or different outstanding model options associated to the Services, together with but not restricted to "DeepSeek," and so on., in any approach, either singly or together. Here’s what to know about DeepSeek, its expertise and its implications. DeepSeek AI is innovating synthetic intelligence technology with its powerful language fashions and versatile products. DeepSeek r1 fashions require high-performance GPUs and enough computational power. DeepSeek is the most recent instance showing the facility of open supply. The DeepSeek crew writes that their work makes it possible to: "draw two conclusions: First, distilling extra highly effective fashions into smaller ones yields glorious outcomes, whereas smaller models counting on the massive-scale RL talked about on this paper require enormous computational energy and may not even obtain the efficiency of distillation. First, utilizing a course of reward mannequin (PRM) to guide reinforcement studying was untenable at scale. By utilizing GRPO to apply the reward to the model, DeepSeek avoids using a large "critic" mannequin; this again saves memory. For example, they used FP8 to considerably scale back the amount of memory required.
It will be fascinating to track the trade-offs as more people use it in numerous contexts. 5.2 Without our permission, you or your end customers shall not use any trademarks, service marks, commerce names, domain names, web site names, firm logos (LOGOs), URLs, or different outstanding model options associated to the Services, together with but not restricted to "DeepSeek," and so on., in any approach, either singly or together. Here’s what to know about DeepSeek, its expertise and its implications. DeepSeek AI is innovating synthetic intelligence technology with its powerful language fashions and versatile products. DeepSeek r1 fashions require high-performance GPUs and enough computational power. DeepSeek is the most recent instance showing the facility of open supply. The DeepSeek crew writes that their work makes it possible to: "draw two conclusions: First, distilling extra highly effective fashions into smaller ones yields glorious outcomes, whereas smaller models counting on the massive-scale RL talked about on this paper require enormous computational energy and may not even obtain the efficiency of distillation. First, utilizing a course of reward mannequin (PRM) to guide reinforcement studying was untenable at scale. By utilizing GRPO to apply the reward to the model, DeepSeek avoids using a large "critic" mannequin; this again saves memory. For example, they used FP8 to considerably scale back the amount of memory required.
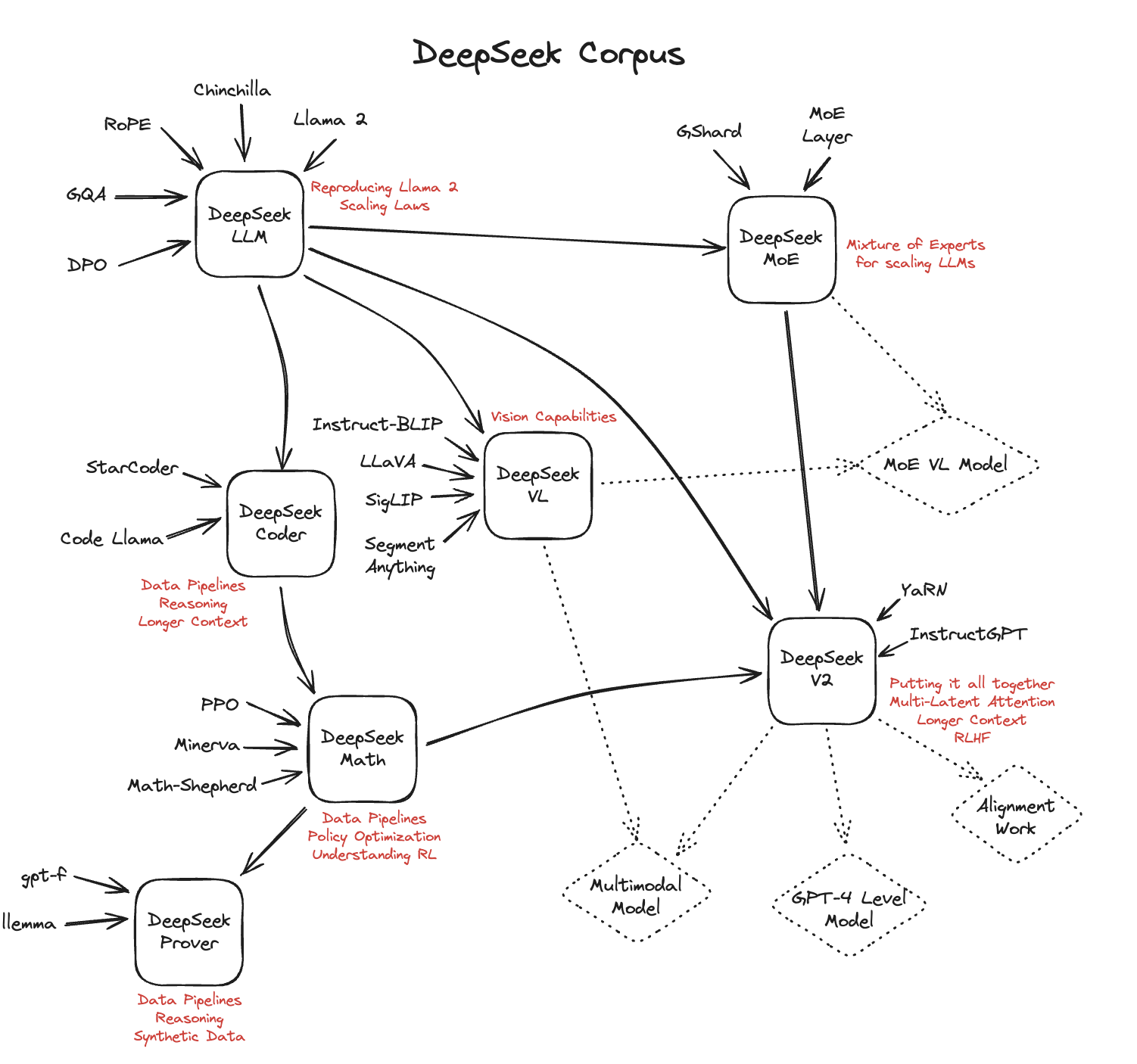 However, previous to this work, FP8 was seen as efficient but much less effective; DeepSeek demonstrated how it can be utilized successfully. "In this work, we introduce an FP8 blended precision training framework and, for the primary time, validate its effectiveness on a particularly giant-scale model. This overlap ensures that, because the model further scales up, as long as we maintain a continuing computation-to-communication ratio, we are able to still make use of fantastic-grained specialists throughout nodes whereas attaining a near-zero all-to-all communication overhead." The fixed computation-to-communication ratio and near-zero all-to-all communication overhead is putting relative to "normal" ways to scale distributed coaching which usually just means "add more hardware to the pile". "As for the training framework, we design the DualPipe algorithm for environment friendly pipeline parallelism, which has fewer pipeline bubbles and hides many of the communication during coaching by computation-communication overlap. Combining these efforts, we achieve high training efficiency." This is a few severely deep work to get the most out of the hardware they had been restricted to.
However, previous to this work, FP8 was seen as efficient but much less effective; DeepSeek demonstrated how it can be utilized successfully. "In this work, we introduce an FP8 blended precision training framework and, for the primary time, validate its effectiveness on a particularly giant-scale model. This overlap ensures that, because the model further scales up, as long as we maintain a continuing computation-to-communication ratio, we are able to still make use of fantastic-grained specialists throughout nodes whereas attaining a near-zero all-to-all communication overhead." The fixed computation-to-communication ratio and near-zero all-to-all communication overhead is putting relative to "normal" ways to scale distributed coaching which usually just means "add more hardware to the pile". "As for the training framework, we design the DualPipe algorithm for environment friendly pipeline parallelism, which has fewer pipeline bubbles and hides many of the communication during coaching by computation-communication overlap. Combining these efforts, we achieve high training efficiency." This is a few severely deep work to get the most out of the hardware they had been restricted to.
What can we study from what didn’t work? What did DeepSeek try that didn’t work? However, GRPO takes a rules-based mostly guidelines approach which, whereas it is going to work better for issues which have an objective reply - equivalent to coding and math - it'd wrestle in domains the place solutions are subjective or variable. ⚡ Boosting productivity with Deep Seek
댓글목록
등록된 댓글이 없습니다.