Seven Romantic Deepseek Chatgpt Ideas
페이지 정보
작성자 Beverly 작성일25-02-27 08:29 조회10회 댓글0건관련링크
본문
Chat Models: DeepSeek-V2 Chat (SFT) and (RL) surpass Qwen1.5 72B Chat on most English, math, and code benchmarks. DeepSeek-V2 is a powerful, open-supply Mixture-of-Experts (MoE) language mannequin that stands out for its economical coaching, efficient inference, and top-tier performance throughout numerous benchmarks. This allows for extra environment friendly computation whereas maintaining high performance, demonstrated through high-tier outcomes on varied benchmarks. The importance of DeepSeek-V2 lies in its capability to deliver robust performance whereas being value-effective and environment friendly. DeepSeek-V2 is considered an "open model" because its mannequin checkpoints, code repository, and different sources are freely accessible and accessible for public use, research, and further development. However, DeepSeek’s ability to attain high efficiency with restricted sources is a testomony to its ingenuity and could pose a protracted-term problem to established players. The rise of DeepSeek inventory marks a turning point in the AI trade, with the potential to reshape market dynamics and challenge established gamers. This supplies a readily available interface with out requiring any setup, making it superb for preliminary testing and exploration of the model’s potential. Investors ought to keep knowledgeable about developments in this space and punctiliously consider opportunities based on long-time period progress potential and market situations.
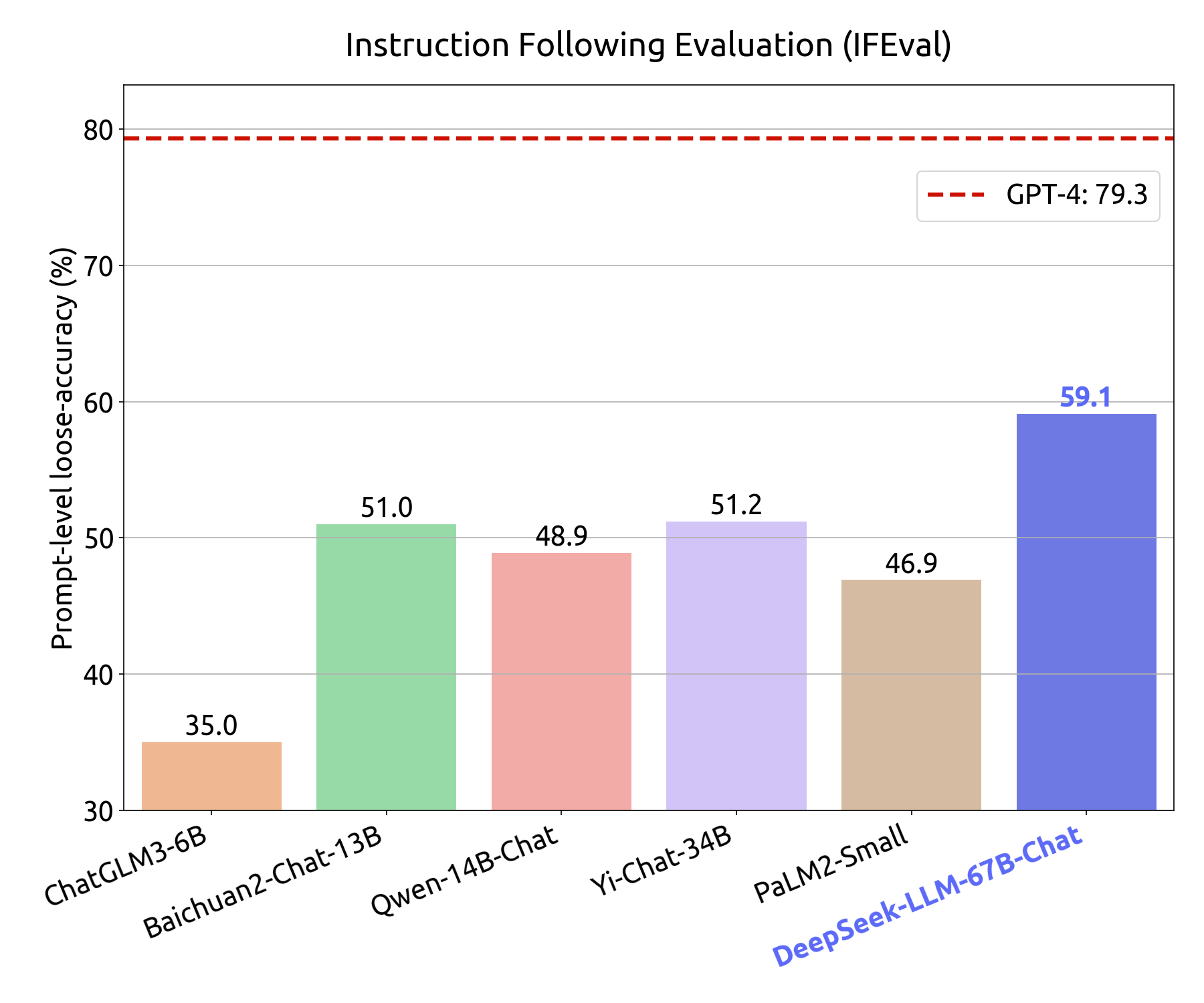 Geopolitical Developments: International trade insurance policies might influence DeepSeek’s development trajectory in key markets. In line with Sunlands' administration, "The widespread utility of DeepSeek will basically remodel the training mannequin. On the learning entrance, students' learning patterns and cognitive processes will endure profound modifications, prompting to embrace new applied sciences with renewed determination. The introduction of DeepSeek's AI mannequin won't only provide students with more personalised, correct, and efficient academic companies but also optimize inside processes, driving sustainable development for the enterprise." Since its launch in January 2025, DeepSeek-R1 has gained international attention, sparking a new wave of innovation in AI expertise. That is achieved via the introduction of Multi-head Latent Attention (MLA), which compresses the KV cache considerably. Multi-Head Latent Attention (MLA): This novel consideration mechanism compresses the key-Value (KV) cache right into a latent vector, which considerably reduces the size of the KV cache throughout inference, enhancing effectivity. Economical Training and Efficient Inference: Compared to its predecessor, DeepSeek-V2 reduces training prices by 42.5%, reduces the KV cache dimension by 93.3%, and will increase maximum generation throughput by 5.76 times. The utmost generation throughput of DeepSeek-V2 is 5.76 instances that of DeepSeek 67B, demonstrating its superior capability to handle bigger volumes of information more effectively.
Geopolitical Developments: International trade insurance policies might influence DeepSeek’s development trajectory in key markets. In line with Sunlands' administration, "The widespread utility of DeepSeek will basically remodel the training mannequin. On the learning entrance, students' learning patterns and cognitive processes will endure profound modifications, prompting to embrace new applied sciences with renewed determination. The introduction of DeepSeek's AI mannequin won't only provide students with more personalised, correct, and efficient academic companies but also optimize inside processes, driving sustainable development for the enterprise." Since its launch in January 2025, DeepSeek-R1 has gained international attention, sparking a new wave of innovation in AI expertise. That is achieved via the introduction of Multi-head Latent Attention (MLA), which compresses the KV cache considerably. Multi-Head Latent Attention (MLA): This novel consideration mechanism compresses the key-Value (KV) cache right into a latent vector, which considerably reduces the size of the KV cache throughout inference, enhancing effectivity. Economical Training and Efficient Inference: Compared to its predecessor, DeepSeek-V2 reduces training prices by 42.5%, reduces the KV cache dimension by 93.3%, and will increase maximum generation throughput by 5.76 times. The utmost generation throughput of DeepSeek-V2 is 5.76 instances that of DeepSeek 67B, demonstrating its superior capability to handle bigger volumes of information more effectively.
However, the release of DeepSeek-V2 showcases China’s advancements in giant language models and foundation fashions, challenging the notion that the US maintains a big lead on this discipline. Large MoE Language Model with Parameter Efficiency: Deepseek Online chat online-V2 has a total of 236 billion parameters, but only activates 21 billion parameters for each token. But DeepSeek developed its large language model without the good thing about essentially the most-superior chips, in accordance with most reports. The company’s R1 mannequin is alleged to cost simply $6 million to prepare- a fraction of what it costs companies like NVIDIA and Microsoft to practice their fashions- and its most highly effective variations price approximately ninety five p.c less than OpenAI and its rivals. DeepSeek’s superiority over the fashions trained by OpenAI, Google and Meta is treated like proof that - after all - big tech is in some way getting what is deserves. Architectural Innovations: DeepSeek-V2 incorporates novel architectural options like MLA for consideration and DeepSeekMoE for handling Feed-Forward Networks (FFNs), both of which contribute to its improved effectivity and effectiveness in coaching strong fashions at lower prices. Performance: DeepSeek-V2 outperforms DeepSeek 67B on almost all benchmarks, attaining stronger performance whereas saving on training costs, lowering the KV cache, and rising the utmost era throughput.
In distinction, DeepSeek's rationalization was "Short-term trade failure: unable to withstand price fluctuations over roughly 10 hours." While DeepSeek’s assessment isn't incorrect, it lacks deeper reasoning. Scalability Concerns: Despite DeepSeek’s price efficiency, it stays unsure whether the corporate can scale its operations to compete with business giants. Global Expansion: If DeepSeek can secure strategic partnerships, it might expand past China and compete on a world scale. Build case narratives: AI can assist with creating case narratives by analyzing case recordsdata and documents, extracting related information, and organizing them into an easy-to-perceive narrative. Users can entry ChatGPT with Free DeepSeek v3 or paid choices under its service ranges. Google Gemini can be available without spending a dime, but free Deep seek versions are limited to older fashions. Former Google CEO Eric Schmidt opined that the US is "way forward of China" in AI, citing elements equivalent to chip shortages, much less Chinese training material, lowered funding, and a deal with the improper areas. LLaMA3 70B: Despite being trained on fewer English tokens, DeepSeek-V2 exhibits a slight gap in basic English capabilities but demonstrates comparable code and math capabilities, and considerably better performance on Chinese benchmarks.
If you're ready to learn more on DeepSeek Chat stop by the internet site.
댓글목록
등록된 댓글이 없습니다.