9 Super Useful Tips To Enhance Deepseek
페이지 정보
작성자 Anja 작성일25-02-27 05:16 조회11회 댓글0건관련링크
본문
DeepSeek immediately launched a brand new giant language model household, the R1 collection, that’s optimized for reasoning tasks. Alongside R1 and R1-Zero, DeepSeek in the present day open-sourced a set of less succesful but extra hardware-environment friendly models. "DeepSeek v3 and in addition DeepSeek v2 earlier than which can be mainly the identical sort of models as GPT-4, however simply with more intelligent engineering tips to get more bang for their buck when it comes to GPUs," Brundage said. GitHub does its half to make it harder to create and operate accounts to buy/sell stars: it has Trust & Safety and Platform Health groups that battle account spam and account farming and are recognized to suspend accounts that abuse its terms and circumstances. Jailbreaks, that are one form of prompt-injection attack, permit individuals to get across the security methods put in place to restrict what an LLM can generate. They’re based mostly on the Llama and Qwen open-source LLM families.
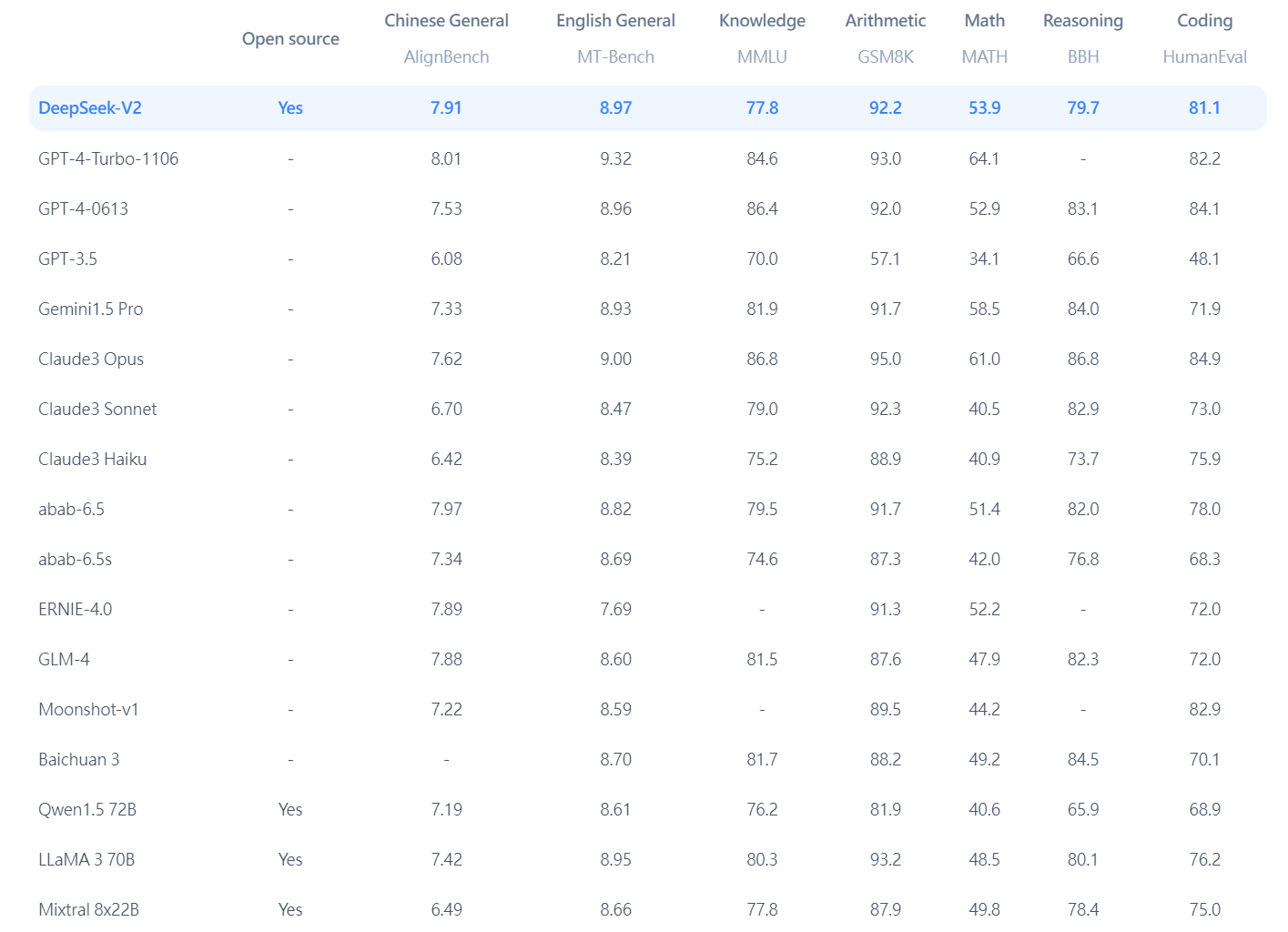 처음에는 Llama 2를 기반으로 다양한 벤치마크에서 주요 모델들을 고르게 앞서나가겠다는 목표로 모델을 개발, 개선하기 시작했습니다. The company says that this alteration helped considerably increase output quality. Although R1-Zero has a sophisticated characteristic set, its output high quality is restricted. Supervised nice-tuning, in turn, boosts the AI’s output quality by providing it with examples of easy methods to perform the task at hand. This workflow makes use of supervised high-quality-tuning, the method that DeepSeek overlooked during the event of R1-Zero. DeepSeek relies in Hangzhou, China, focusing on the development of artificial basic intelligence (AGI). The Chinese synthetic intelligence developer has made the algorithms’ source-code out there on Hugging Face. The Chinese mannequin-maker has panicked traders. Two months after questioning whether LLMs have hit a plateau, the reply seems to be a definite "no." Google’s Gemini 2.0 LLM and Veo 2 video mannequin is spectacular, OpenAI previewed a succesful o3 model, and Chinese startup DeepSeek unveiled a frontier mannequin that price less than $6M to prepare from scratch. When the mannequin relieves a immediate, a mechanism often called a router sends the question to the neural network best-geared up to process it. When customers enter a prompt into an MoE mannequin, the question doesn’t activate the complete AI but only the precise neural network that can generate the response.
처음에는 Llama 2를 기반으로 다양한 벤치마크에서 주요 모델들을 고르게 앞서나가겠다는 목표로 모델을 개발, 개선하기 시작했습니다. The company says that this alteration helped considerably increase output quality. Although R1-Zero has a sophisticated characteristic set, its output high quality is restricted. Supervised nice-tuning, in turn, boosts the AI’s output quality by providing it with examples of easy methods to perform the task at hand. This workflow makes use of supervised high-quality-tuning, the method that DeepSeek overlooked during the event of R1-Zero. DeepSeek relies in Hangzhou, China, focusing on the development of artificial basic intelligence (AGI). The Chinese synthetic intelligence developer has made the algorithms’ source-code out there on Hugging Face. The Chinese mannequin-maker has panicked traders. Two months after questioning whether LLMs have hit a plateau, the reply seems to be a definite "no." Google’s Gemini 2.0 LLM and Veo 2 video mannequin is spectacular, OpenAI previewed a succesful o3 model, and Chinese startup DeepSeek unveiled a frontier mannequin that price less than $6M to prepare from scratch. When the mannequin relieves a immediate, a mechanism often called a router sends the question to the neural network best-geared up to process it. When customers enter a prompt into an MoE mannequin, the question doesn’t activate the complete AI but only the precise neural network that can generate the response.
Customization: DeepSeek may be tailored to specific industries, equivalent to healthcare, finance, or e-commerce, making certain it meets unique enterprise needs. While the U.S. government has attempted to regulate the AI business as a whole, Free DeepSeek it has little to no oversight over what particular AI fashions actually generate. Nous-Hermes-Llama2-13b is a state-of-the-art language model advantageous-tuned on over 300,000 directions. A MoE mannequin includes a number of neural networks which might be each optimized for a special set of tasks. Multiple quantisation parameters are supplied, to permit you to decide on the perfect one on your hardware and requirements. The distilled fashions range in size from 1.5 billion to 70 billion parameters. Both LLMs function a mixture of specialists, or MoE, architecture with 671 billion parameters. This characteristic gives it an incredible benefit in situations equivalent to text era and machine translation in pure language processing. Other libraries that lack this function can only run with a 4K context length. Projects with high traction were more likely to draw investment as a result of buyers assumed that developers’ curiosity can finally be monetized. Some are doubtless used for progress hacking to secure investment, while some are deployed for "resume fraud:" making it seem a software program engineer’s aspect project on GitHub is a lot more popular than it truly is!
I think that's why a lot of people concentrate to it,' Mr Heim stated. In any case, we'd like the total vectors for attention to work, not their latents. "It is the primary open analysis to validate that reasoning capabilities of LLMs can be incentivized purely by way of RL, without the need for SFT," DeepSeek researchers detailed. AiFort supplies adversarial testing, competitive benchmarking, and steady monitoring capabilities to protect AI purposes in opposition to adversarial assaults to make sure compliance and accountable AI applications. The model is optimized for writing, instruction-following, and coding duties, introducing function calling capabilities for external instrument interaction. Up till this level, Deepseek AI Online Chat within the transient history of coding assistants utilizing GenAI-based code, essentially the most capable models have at all times been closed source and accessible only by the APIs of frontier mannequin developers like Open AI and Anthropic. Deepseek Online chat's hiring preferences target technical talents slightly than work experience; most new hires are both current college graduates or developers whose AI careers are much less established. A reminder that getting "clever" with corporate perks can wreck in any other case lucrative careers at Big Tech. The Pulse is a sequence masking insights, patterns, and tendencies inside Big Tech and startups. Middle manager burnout incoming? A Forbes article suggests a broader middle supervisor burnout to come throughout most skilled sectors.
If you have any sort of questions regarding where and the best ways to utilize free Deep Seek, you can call us at our own website.
댓글목록
등록된 댓글이 없습니다.