The last Word Secret Of Deepseek
페이지 정보
작성자 Richard 작성일25-02-27 02:09 조회8회 댓글0건관련링크
본문
This sounds lots like what OpenAI did for o1: DeepSeek started the model out with a bunch of examples of chain-of-thought thinking so it might be taught the proper format for human consumption, and then did the reinforcement studying to enhance its reasoning, along with quite a few editing and refinement steps; the output is a model that appears to be very aggressive with o1. It is a visitor post from Ty Dunn, Co-founding father of Continue, that covers the right way to set up, explore, and determine the easiest way to make use of Continue and Ollama together. Succeeding at this benchmark would show that an LLM can dynamically adapt its knowledge to handle evolving code APIs, rather than being limited to a fixed set of capabilities. We used the accuracy on a selected subset of the MATH check set because the evaluation metric. The paper presents the CodeUpdateArena benchmark to check how effectively massive language models (LLMs) can update their information about code APIs that are repeatedly evolving.
 Large language models (LLMs) are highly effective instruments that can be used to generate and understand code. The paper presents a new benchmark known as CodeUpdateArena to test how nicely LLMs can update their data to handle adjustments in code APIs. The paper presents a new massive language mannequin called DeepSeekMath 7B that's specifically designed to excel at mathematical reasoning. The paper introduces DeepSeekMath 7B, a large language model that has been pre-skilled on a massive quantity of math-associated knowledge from Common Crawl, totaling a hundred and twenty billion tokens. In this scenario, you possibly can count on to generate roughly 9 tokens per second. First, they gathered an enormous quantity of math-related knowledge from the online, including 120B math-related tokens from Common Crawl. The paper attributes the robust mathematical reasoning capabilities of DeepSeekMath 7B to 2 key factors: the extensive math-related knowledge used for pre-training and the introduction of the GRPO optimization method. By leveraging an enormous quantity of math-associated web data and introducing a novel optimization method referred to as Group Relative Policy Optimization (GRPO), the researchers have achieved impressive outcomes on the challenging MATH benchmark. The paper attributes the model's mathematical reasoning talents to two key components: leveraging publicly out there net knowledge and introducing a novel optimization technique called Group Relative Policy Optimization (GRPO).
Large language models (LLMs) are highly effective instruments that can be used to generate and understand code. The paper presents a new benchmark known as CodeUpdateArena to test how nicely LLMs can update their data to handle adjustments in code APIs. The paper presents a new massive language mannequin called DeepSeekMath 7B that's specifically designed to excel at mathematical reasoning. The paper introduces DeepSeekMath 7B, a large language model that has been pre-skilled on a massive quantity of math-associated knowledge from Common Crawl, totaling a hundred and twenty billion tokens. In this scenario, you possibly can count on to generate roughly 9 tokens per second. First, they gathered an enormous quantity of math-related knowledge from the online, including 120B math-related tokens from Common Crawl. The paper attributes the robust mathematical reasoning capabilities of DeepSeekMath 7B to 2 key factors: the extensive math-related knowledge used for pre-training and the introduction of the GRPO optimization method. By leveraging an enormous quantity of math-associated web data and introducing a novel optimization method referred to as Group Relative Policy Optimization (GRPO), the researchers have achieved impressive outcomes on the challenging MATH benchmark. The paper attributes the model's mathematical reasoning talents to two key components: leveraging publicly out there net knowledge and introducing a novel optimization technique called Group Relative Policy Optimization (GRPO).
 The important thing innovation on this work is the use of a novel optimization approach known as Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. GRPO helps the model develop stronger mathematical reasoning abilities while also enhancing its reminiscence utilization, making it more efficient. The DEEPSEEKAI token is a fan-pushed initiative, and while it shares the identify, it does not characterize Deepseek Online chat’s technology or providers. Moreover, Taiwan’s public debt has fallen considerably since peaking in 2012. While central government frugality is often highly commendable, this policy is wildly inappropriate for Taiwan, given its unique circumstances. Second, the researchers launched a new optimization method known as Group Relative Policy Optimization (GRPO), which is a variant of the nicely-recognized Proximal Policy Optimization (PPO) algorithm. Additionally, the paper does not tackle the potential generalization of the GRPO method to different sorts of reasoning duties past arithmetic. However, there are a number of potential limitations and areas for additional research that could possibly be thought-about. However, accuracy may fluctuate barely. For those who worth integration and ease of use, Cursor AI with Claude 3.5 Sonnet might be the higher possibility. Users are empowered to entry, use, and modify the source code for gratis.
The important thing innovation on this work is the use of a novel optimization approach known as Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. GRPO helps the model develop stronger mathematical reasoning abilities while also enhancing its reminiscence utilization, making it more efficient. The DEEPSEEKAI token is a fan-pushed initiative, and while it shares the identify, it does not characterize Deepseek Online chat’s technology or providers. Moreover, Taiwan’s public debt has fallen considerably since peaking in 2012. While central government frugality is often highly commendable, this policy is wildly inappropriate for Taiwan, given its unique circumstances. Second, the researchers launched a new optimization method known as Group Relative Policy Optimization (GRPO), which is a variant of the nicely-recognized Proximal Policy Optimization (PPO) algorithm. Additionally, the paper does not tackle the potential generalization of the GRPO method to different sorts of reasoning duties past arithmetic. However, there are a number of potential limitations and areas for additional research that could possibly be thought-about. However, accuracy may fluctuate barely. For those who worth integration and ease of use, Cursor AI with Claude 3.5 Sonnet might be the higher possibility. Users are empowered to entry, use, and modify the source code for gratis.
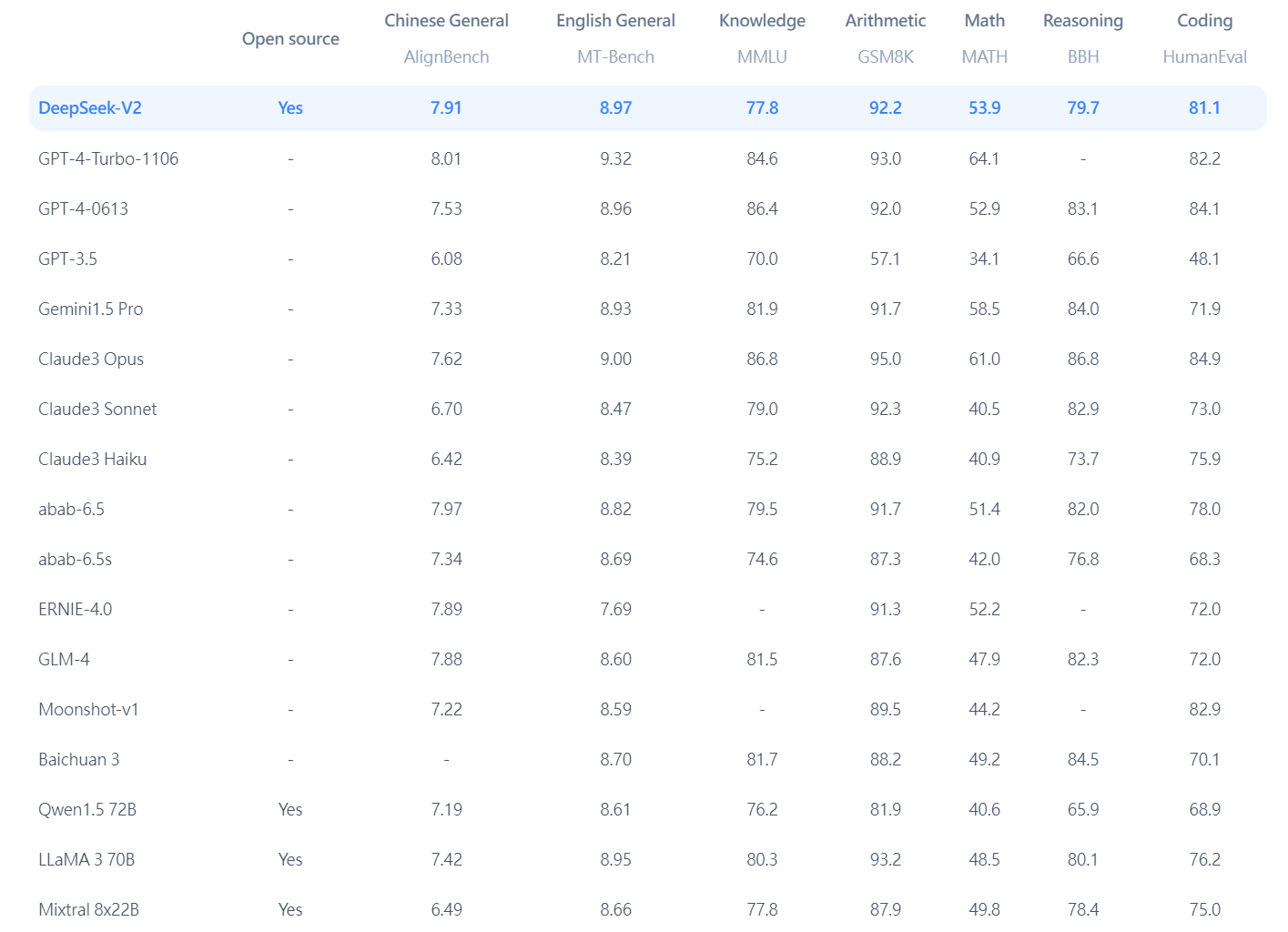
There are a number of AI coding assistants on the market but most cost cash to entry from an IDE. Neither Feroot nor the opposite researchers noticed information transferred to China Mobile when testing logins in North America, but they couldn't rule out that data for some users was being transferred to the Chinese telecom. We don't store person conversations or DeepSeek Chat any input information on our servers. If it’s potential to build advanced DeepSeek Ai Chat models at a low price, it may essentially challenge the prevailing US approach to AI growth-which involves investing billions of dollars in data centers, advanced chips, and high-performance infrastructure. The outcomes are impressive: DeepSeekMath 7B achieves a score of 51.7% on the challenging MATH benchmark, approaching the performance of slicing-edge fashions like Gemini-Ultra and GPT-4. The dataset is constructed by first prompting GPT-four to generate atomic and executable function updates throughout 54 features from 7 numerous Python packages. This performance level approaches that of state-of-the-artwork fashions like Gemini-Ultra and GPT-4. The fashions are evaluated across several categories, including English, Code, Math, and Chinese tasks. The issue units are also open-sourced for additional research and comparison.
댓글목록
등록된 댓글이 없습니다.