6 Finest Tweets Of All Time About Deepseek
페이지 정보
작성자 Alysa 작성일25-02-23 10:49 조회5회 댓글0건관련링크
본문
DeepSeek V3 is computationally efficient, reaching focused activation based mostly on desired tasks with out incurring hefty costs. Subsequent supervised high-quality-tuning (SFT) was performed on 1.5 million samples, covering each reasoning (math, programming, logic) and non-reasoning duties. Similarly, even 3.5 Sonnet claims to offer efficient computing capabilities, significantly for coding and agentic duties. As DeepSeek has began gaining attention, compared to global tech leaders like Microsoft, Intel, and even OpenAI, an apparent question arises-is it better than others? To make use of it, you merely kind a query in pure language, simply as you would ask an individual. Together AI first emerged in 2023 with an purpose to simplify enterprise use of open-supply giant language fashions (LLMs). Tanishq Abraham, former research director at Stability AI, stated he was not shocked by China’s degree of progress in AI given the rollout of varied models by Chinese companies resembling Alibaba and Baichuan. On Monday, Nvidia, which holds a near-monopoly on producing the semiconductors that power generative AI, misplaced nearly $600bn in market capitalisation after its shares plummeted 17 %. While it has caused an AI energy shift towards the East, it has also exposed the new AI mannequin to safety challenges. While it is simply too soon to reply this query, let’s have a look at DeepSeek V3 against a number of different AI language models to get an concept.
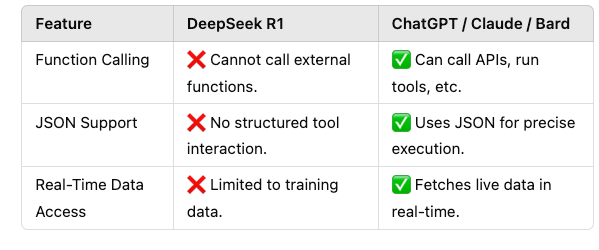 While information on DeepSeek’s efficiency on industry benchmarks has been publicly out there since the beginning, OpenAI has only just lately launched it for a number of benchmarks: GPT-four Preview, Turbo, and 4o. Here is the crux of the matter. However, info on the training knowledge of OpenAI’s newest model, ChatGPT-four Turbo, just isn't publicly out there. On January 30, 2025, a serious data breach uncovered over a million log lines, including chat histories, secret keys, and backend information. He was additionally answerable for projects of the most important monetary institutions in Europe, with the smallest undertaking being price over €50 million. DeepSeek was able to capitalize on the increased flow of funding for AI builders, the efforts over the years to construct up Chinese university STEM packages, and the velocity of commercialization of new applied sciences. Instead, he focused on PhD students from China’s top universities, together with Peking University and Tsinghua University, who were wanting to prove themselves. Scholars like MIT professor Huang Yasheng attribute the rise of China’s tech sector to the numerous collaborations it has had with other international locations. While some applaud DeepSeek’s speedy progress, others are wary of the risks-the spread of misinformation, security vulnerabilities, and China’s rising influence in AI.
While information on DeepSeek’s efficiency on industry benchmarks has been publicly out there since the beginning, OpenAI has only just lately launched it for a number of benchmarks: GPT-four Preview, Turbo, and 4o. Here is the crux of the matter. However, info on the training knowledge of OpenAI’s newest model, ChatGPT-four Turbo, just isn't publicly out there. On January 30, 2025, a serious data breach uncovered over a million log lines, including chat histories, secret keys, and backend information. He was additionally answerable for projects of the most important monetary institutions in Europe, with the smallest undertaking being price over €50 million. DeepSeek was able to capitalize on the increased flow of funding for AI builders, the efforts over the years to construct up Chinese university STEM packages, and the velocity of commercialization of new applied sciences. Instead, he focused on PhD students from China’s top universities, together with Peking University and Tsinghua University, who were wanting to prove themselves. Scholars like MIT professor Huang Yasheng attribute the rise of China’s tech sector to the numerous collaborations it has had with other international locations. While some applaud DeepSeek’s speedy progress, others are wary of the risks-the spread of misinformation, security vulnerabilities, and China’s rising influence in AI.
While DeepSeek focuses on English and Chinese, 3.5 Sonnet was designed for broad multilingual fluency and to cater to a wide range of languages and contexts. It underwent pre-training on an unlimited dataset of 14.8 trillion tokens, encompassing multiple languages with a deal with English and Chinese. Both LLMs assist multiple languages, but DeepSeek is extra optimized for English and Chinese-language reasoning. Persistent execution stack. To speed up the upkeep of a number of parallel stacks throughout splitting and merging resulting from a number of potential expansion paths, we design a tree-based knowledge structure that efficiently manages multiple stacks together. Details about Gemini’s specific training knowledge are proprietary and never publicly disclosed. This pushed the boundaries of its safety constraints and explored whether or not it could be manipulated into offering truly helpful and actionable details about malware creation. Further particulars about training information are proprietary and never publicly disclosed. In this neural community design, numerous skilled models (sub-networks) handle totally different tasks/tokens, but solely selective ones are activated (utilizing gating mechanisms) at a time based on the input. Additionally, the latter is predicated on a DNN (deep neural community) that makes use of a transformer architecture. 3.5 Sonnet relies on a GPT (generative pre-skilled transformer) mannequin.
Claude 3.5 Sonnet is one other reputed LLM developed and maintained by Anthropic. In this text, we will explore how to use a slicing-edge LLM hosted in your machine to connect it to VSCode for a powerful free self-hosted Copilot or Cursor experience with out sharing any info with third-celebration companies. We firmly imagine that beneath the management of the Party, cross-strait relations will continue to maneuver in the direction of peaceful reunification, and this will undoubtedly have a constructive impact on the financial development of your complete region. Until DeepSeek formally discloses how it achieved this breakthrough, hypothesis will continue, and so will the debates round its affect. But because the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections look like far behind these of its established competitors. The most recent mannequin, DeepSeek V3, has been trained on 671 billion parameters with 37 billion activated per token. While V3 is a publicly available model, Gemini 2.0 Flash (experimental) is a closed-source mannequin accessible through platforms like Google AI Studio and Vertex AI. While V3 is publicly out there, Claude 3.5 Sonnet is a closed-source mannequin accessible via APIs like Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI.
댓글목록
등록된 댓글이 없습니다.