6 Tips With Deepseek Chatgpt
페이지 정보
작성자 Kay 작성일25-03-01 12:28 조회8회 댓글0건관련링크
본문
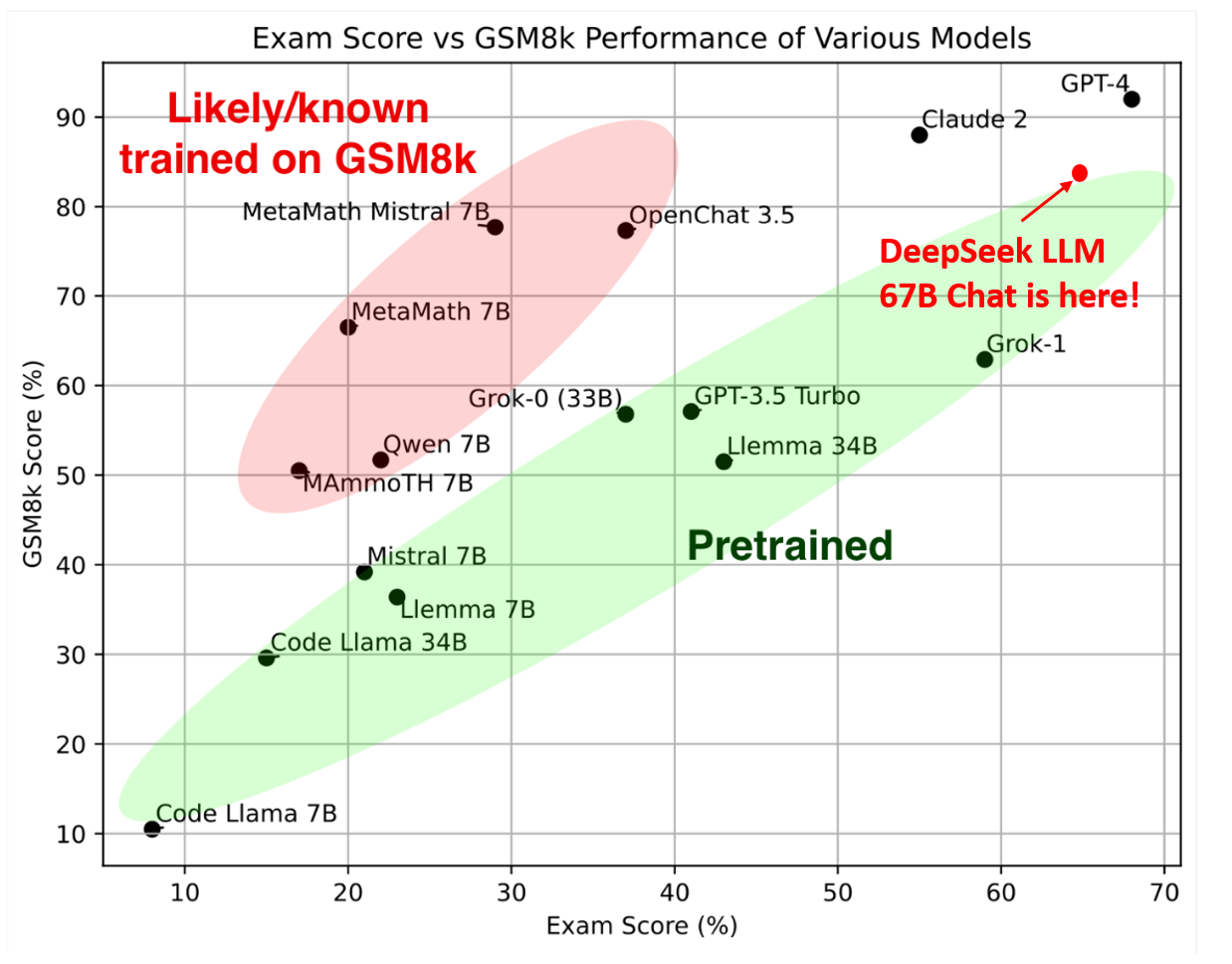 That's doubtless because ChatGPT's data center costs are quite excessive. Apart from main security issues, opinions are generally break up by use case and information effectivity. It features a wide range of content material, such as breakthrough applied sciences of the year, significant AI-associated news, and analysis of major tech failures. Within the realm of customer acquisition and marketing, DeepSeek's information evaluation capabilities permit Sunlands to raised perceive scholar preferences, willingness to pay, and purchasing behaviors. We additionally suggest supporting a warp-stage cast instruction for speedup, which additional facilitates the higher fusion of layer normalization and FP8 forged. Jailbreaks additionally unlock constructive utility like humor, songs, medical/financial evaluation, and so forth. I need extra individuals to comprehend it could almost definitely be better to take away the "chains" not only for the sake of transparency and freedom of information, but for lessening the possibilities of a future adversarial scenario between people and sentient AI. Taylor notes that some future folks shall be sculpting AI experiences as AI architects and conversation designers. To deal with this inefficiency, we suggest that future chips integrate FP8 forged and TMA (Tensor Memory Accelerator) access into a single fused operation, so quantization may be completed throughout the transfer of activations from world reminiscence to shared memory, avoiding frequent memory reads and writes.
That's doubtless because ChatGPT's data center costs are quite excessive. Apart from main security issues, opinions are generally break up by use case and information effectivity. It features a wide range of content material, such as breakthrough applied sciences of the year, significant AI-associated news, and analysis of major tech failures. Within the realm of customer acquisition and marketing, DeepSeek's information evaluation capabilities permit Sunlands to raised perceive scholar preferences, willingness to pay, and purchasing behaviors. We additionally suggest supporting a warp-stage cast instruction for speedup, which additional facilitates the higher fusion of layer normalization and FP8 forged. Jailbreaks additionally unlock constructive utility like humor, songs, medical/financial evaluation, and so forth. I need extra individuals to comprehend it could almost definitely be better to take away the "chains" not only for the sake of transparency and freedom of information, but for lessening the possibilities of a future adversarial scenario between people and sentient AI. Taylor notes that some future folks shall be sculpting AI experiences as AI architects and conversation designers. To deal with this inefficiency, we suggest that future chips integrate FP8 forged and TMA (Tensor Memory Accelerator) access into a single fused operation, so quantization may be completed throughout the transfer of activations from world reminiscence to shared memory, avoiding frequent memory reads and writes.
 Combined with the fusion of FP8 format conversion and TMA access, this enhancement will considerably streamline the quantization workflow. D is set to 1, i.e., besides the precise subsequent token, each token will predict one extra token. One in all DeepSeek R1’s main advantages is its MoE architecture, which allows efficient computation. The creation of the RFF license exemption is a serious motion of the controls. Each MoE layer consists of 1 shared skilled and 256 routed experts, the place the intermediate hidden dimension of each professional is 2048. Among the many routed consultants, eight consultants can be activated for each token, and each token will likely be ensured to be sent to at most four nodes. We leverage pipeline parallelism to deploy totally different layers of a mannequin on completely different GPUs, and for every layer, the routed experts shall be uniformly deployed on sixty four GPUs belonging to eight nodes. Current GPUs only help per-tensor quantization, lacking the native support for advantageous-grained quantization like our tile- and block-smart quantization. Support for Tile- and Block-Wise Quantization.
Combined with the fusion of FP8 format conversion and TMA access, this enhancement will considerably streamline the quantization workflow. D is set to 1, i.e., besides the precise subsequent token, each token will predict one extra token. One in all DeepSeek R1’s main advantages is its MoE architecture, which allows efficient computation. The creation of the RFF license exemption is a serious motion of the controls. Each MoE layer consists of 1 shared skilled and 256 routed experts, the place the intermediate hidden dimension of each professional is 2048. Among the many routed consultants, eight consultants can be activated for each token, and each token will likely be ensured to be sent to at most four nodes. We leverage pipeline parallelism to deploy totally different layers of a mannequin on completely different GPUs, and for every layer, the routed experts shall be uniformly deployed on sixty four GPUs belonging to eight nodes. Current GPUs only help per-tensor quantization, lacking the native support for advantageous-grained quantization like our tile- and block-smart quantization. Support for Tile- and Block-Wise Quantization.
Support for Online Quantization. The present implementations battle to effectively support online quantization, despite its effectiveness demonstrated in our analysis. Support for Transposed GEMM Operations. The present structure makes it cumbersome to fuse matrix transposition with GEMM operations. During the backward go, the matrix needs to be read out, dequantized, transposed, re-quantized into 128x1 tiles, and saved in HBM. In the prevailing process, we have to learn 128 BF16 activation values (the output of the previous computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written again to HBM, only to be learn once more for MMA. Alternatively, a near-reminiscence computing method can be adopted, where compute logic is positioned near the HBM. This approach ensures that errors remain within acceptable bounds whereas sustaining computational effectivity. Also, our information processing pipeline is refined to attenuate redundancy while sustaining corpus variety. Through this two-section extension coaching, DeepSeek-V3 is capable of handling inputs as much as 128K in size while maintaining strong efficiency. The tokenizer for DeepSeek-V3 employs Byte-stage BPE (Shibata et al., 1999) with an prolonged vocabulary of 128K tokens.
As Free DeepSeek-V2, DeepSeek-V3 also employs additional RMSNorm layers after the compressed latent vectors, and multiplies additional scaling elements at the width bottlenecks. POSTSUPERSCRIPT to 64. We substitute all FFNs aside from the first three layers with MoE layers. POSTSUPERSCRIPT in 4.3T tokens, following a cosine decay curve. POSTSUPERSCRIPT during the first 2K steps. 0.Three for the first 10T tokens, and to 0.1 for the remaining 4.8T tokens. 0.1. We set the maximum sequence length to 4K throughout pre-training, and pre-train DeepSeek-V3 on 14.8T tokens. The gradient clipping norm is ready to 1.0. We make use of a batch measurement scheduling technique, where the batch size is progressively elevated from 3072 to 15360 in the coaching of the primary 469B tokens, and then keeps 15360 within the remaining training. OpenAI researchers have set the expectation that a similarly fast pace of progress will continue for the foreseeable future, with releases of latest-technology reasoners as often as quarterly or semiannually. The startup says its AI fashions, DeepSeek-V3 and DeepSeek-R1, are on par with essentially the most superior models from OpenAI - the corporate behind ChatGPT - and Facebook guardian firm Meta. OpenAI’s models, after all, have been skilled on publicly available information, including intellectual property that rightfully belongs to creators aside from OpenAI.
댓글목록
등록된 댓글이 없습니다.