Assured No Stress Deepseek
페이지 정보
작성자 Lelia 작성일25-01-31 07:38 조회8회 댓글0건관련링크
본문
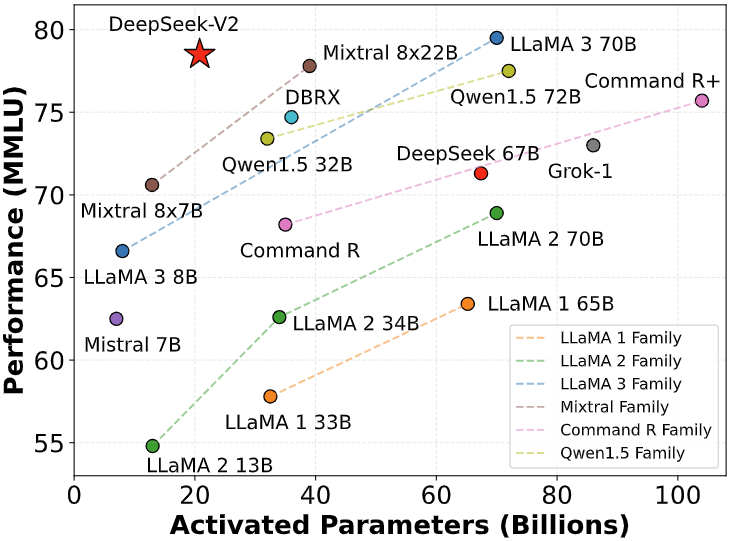 From day one, DeepSeek built its own data middle clusters for model coaching. 33b-instruct is a 33B parameter model initialized from deepseek-coder-33b-base and wonderful-tuned on 2B tokens of instruction data. He is the CEO of a hedge fund known as High-Flyer, which makes use of AI to analyse financial information to make funding decisons - what is called quantitative trading. It forced DeepSeek’s home competitors, together with ByteDance and Alibaba, to chop the utilization prices for a few of their models, and make others utterly free. DeepSeek’s AI models, which have been skilled using compute-environment friendly strategies, have led Wall Street analysts - and technologists - to query whether or not the U.S. There's a draw back to R1, DeepSeek V3, and DeepSeek’s different fashions, nonetheless. As for what DeepSeek’s future may hold, it’s not clear. However, with 22B parameters and a non-manufacturing license, it requires fairly a bit of VRAM and might only be used for analysis and testing purposes, so it won't be the best match for every day local utilization.
From day one, DeepSeek built its own data middle clusters for model coaching. 33b-instruct is a 33B parameter model initialized from deepseek-coder-33b-base and wonderful-tuned on 2B tokens of instruction data. He is the CEO of a hedge fund known as High-Flyer, which makes use of AI to analyse financial information to make funding decisons - what is called quantitative trading. It forced DeepSeek’s home competitors, together with ByteDance and Alibaba, to chop the utilization prices for a few of their models, and make others utterly free. DeepSeek’s AI models, which have been skilled using compute-environment friendly strategies, have led Wall Street analysts - and technologists - to query whether or not the U.S. There's a draw back to R1, DeepSeek V3, and DeepSeek’s different fashions, nonetheless. As for what DeepSeek’s future may hold, it’s not clear. However, with 22B parameters and a non-manufacturing license, it requires fairly a bit of VRAM and might only be used for analysis and testing purposes, so it won't be the best match for every day local utilization.
 Open source and free for research and industrial use. Remember the 3rd drawback about the WhatsApp being paid to make use of? It virtually feels like the character or submit-coaching of the model being shallow makes it really feel like the mannequin has extra to offer than it delivers. That’s much more shocking when contemplating that the United States has worked for years to limit the provision of high-power AI chips to China, citing national security concerns. That means DeepSeek was supposedly able to achieve its low-value model on relatively underneath-powered AI chips. AI race and whether or not the demand for AI chips will maintain. If we get this right, everyone can be able to attain extra and train more of their own company over their own intellectual world. DeepSeek’s success in opposition to larger and extra established rivals has been described as "upending AI" and ushering in "a new era of AI brinkmanship." The company’s success was a minimum of partially responsible for causing Nvidia’s stock value to drop by 18% on Monday, and for eliciting a public response from OpenAI CEO Sam Altman. Equally spectacular is DeepSeek’s R1 "reasoning" mannequin.
Open source and free for research and industrial use. Remember the 3rd drawback about the WhatsApp being paid to make use of? It virtually feels like the character or submit-coaching of the model being shallow makes it really feel like the mannequin has extra to offer than it delivers. That’s much more shocking when contemplating that the United States has worked for years to limit the provision of high-power AI chips to China, citing national security concerns. That means DeepSeek was supposedly able to achieve its low-value model on relatively underneath-powered AI chips. AI race and whether or not the demand for AI chips will maintain. If we get this right, everyone can be able to attain extra and train more of their own company over their own intellectual world. DeepSeek’s success in opposition to larger and extra established rivals has been described as "upending AI" and ushering in "a new era of AI brinkmanship." The company’s success was a minimum of partially responsible for causing Nvidia’s stock value to drop by 18% on Monday, and for eliciting a public response from OpenAI CEO Sam Altman. Equally spectacular is DeepSeek’s R1 "reasoning" mannequin.
This resulted within the RL model. Superior Model Performance: State-of-the-artwork efficiency among publicly obtainable code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks. Noteworthy benchmarks corresponding to MMLU, CMMLU, and C-Eval showcase exceptional outcomes, showcasing DeepSeek LLM’s adaptability to diverse analysis methodologies. DeepSeek-V2, a general-function text- and picture-analyzing system, performed properly in various AI benchmarks - and was far cheaper to run than comparable models at the time. The training run was primarily based on a Nous approach called Distributed Training Over-the-Internet (DisTro, Import AI 384) and Nous has now revealed further particulars on this method, which I’ll cover shortly. The pleasure around DeepSeek-R1 isn't just due to its capabilities but additionally because it is open-sourced, permitting anyone to obtain and run it domestically. The new AI model was developed by DeepSeek, a startup that was born just a yr in the past and has one way or the other managed a breakthrough that famed tech investor Marc Andreessen has referred to as "AI’s Sputnik moment": R1 can almost match the capabilities of its way more famous rivals, including OpenAI’s GPT-4, Meta’s Llama and Google’s Gemini - but at a fraction of the fee. Like other AI startups, including Anthropic and Perplexity, DeepSeek launched varied aggressive AI fashions over the previous 12 months which have captured some industry consideration.
deepseek (read this blog post from bikeindex.org) unveiled its first set of fashions - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. Nevertheless it wasn’t till final spring, when the startup released its next-gen DeepSeek-V2 family of models, that the AI trade started to take discover. Once I started utilizing Vite, I never used create-react-app ever again. In 2023, High-Flyer began DeepSeek as a lab devoted to researching AI instruments separate from its monetary business. With High-Flyer as certainly one of its traders, the lab spun off into its own firm, additionally known as DeepSeek. Chinese AI lab DeepSeek broke into the mainstream consciousness this week after its chatbot app rose to the top of the Apple App Store charts. Being Chinese-developed AI, they’re subject to benchmarking by China’s internet regulator to ensure that its responses "embody core socialist values." In DeepSeek’s chatbot app, for instance, R1 won’t reply questions about Tiananmen Square or deepseek ai Taiwan’s autonomy. Whatever the case may be, developers have taken to DeepSeek’s models, which aren’t open source as the phrase is usually understood but are available below permissive licenses that allow for commercial use. "In the primary stage, two separate specialists are educated: one that learns to rise up from the ground and one other that learns to score against a hard and fast, random opponent.
댓글목록
등록된 댓글이 없습니다.