GitHub - Deepseek-ai/DeepSeek-LLM: DeepSeek LLM: let there Be Answers
페이지 정보
작성자 Libby Bostic 작성일25-01-31 10:22 조회6회 댓글0건관련링크
본문
 Interested by what makes DeepSeek so irresistible? DeepSeek and ChatGPT: what are the principle differences? Note: The full measurement of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the principle Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. This type of mindset is fascinating because it is a symptom of believing that effectively using compute - and many it - is the primary determining factor in assessing algorithmic progress. 2. Extend context size from 4K to 128K utilizing YaRN. Note that a lower sequence size doesn't restrict the sequence size of the quantised model. Please word that there may be slight discrepancies when utilizing the converted HuggingFace models. Since implementation, there have been numerous instances of the AIS failing to assist its supposed mission. Our evaluation indicates that there is a noticeable tradeoff between content management and worth alignment on the one hand, and the chatbot’s competence to reply open-ended questions on the other. In China, however, alignment coaching has change into a powerful tool for the Chinese authorities to restrict the chatbots: to cross the CAC registration, Chinese developers must wonderful tune their models to align with "core socialist values" and Beijing’s standard of political correctness.
Interested by what makes DeepSeek so irresistible? DeepSeek and ChatGPT: what are the principle differences? Note: The full measurement of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the principle Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. This type of mindset is fascinating because it is a symptom of believing that effectively using compute - and many it - is the primary determining factor in assessing algorithmic progress. 2. Extend context size from 4K to 128K utilizing YaRN. Note that a lower sequence size doesn't restrict the sequence size of the quantised model. Please word that there may be slight discrepancies when utilizing the converted HuggingFace models. Since implementation, there have been numerous instances of the AIS failing to assist its supposed mission. Our evaluation indicates that there is a noticeable tradeoff between content management and worth alignment on the one hand, and the chatbot’s competence to reply open-ended questions on the other. In China, however, alignment coaching has change into a powerful tool for the Chinese authorities to restrict the chatbots: to cross the CAC registration, Chinese developers must wonderful tune their models to align with "core socialist values" and Beijing’s standard of political correctness.
With the combination of value alignment training and keyword filters, Chinese regulators have been capable of steer chatbots’ responses to favor Beijing’s most well-liked value set. The keyword filter is an extra layer of safety that is attentive to delicate terms akin to names of CCP leaders and prohibited topics like Taiwan and ديب سيك Tiananmen Square. For international researchers, there’s a approach to avoid the keyword filters and test Chinese models in a less-censored environment. The cost of decentralization: An important caveat to all of that is none of this comes free of charge - training models in a distributed approach comes with hits to the efficiency with which you light up each GPU throughout coaching. Before we perceive and evaluate deepseeks performance, here’s a quick overview on how fashions are measured on code particular duties. The pre-coaching course of, with particular particulars on coaching loss curves and benchmark metrics, is released to the public, emphasising transparency and accessibility. As a result, we made the choice to not incorporate MC information within the pre-coaching or wonderful-tuning course of, as it would lead to overfitting on benchmarks. The Sapiens models are good due to scale - specifically, heaps of knowledge and plenty of annotations. This disparity could possibly be attributed to their training data: English and Chinese discourses are influencing the coaching information of these models.
They generate different responses on Hugging Face and on the China-dealing with platforms, give completely different solutions in English and Chinese, and typically change their stances when prompted multiple instances in the same language. TextWorld: An entirely textual content-primarily based game with no visible component, the place the agent has to explore mazes and work together with on a regular basis objects by way of natural language (e.g., "cook potato with oven"). The an increasing number of jailbreak research I read, the more I think it’s largely going to be a cat and mouse game between smarter hacks and models getting smart sufficient to know they’re being hacked - and proper now, for this type of hack, the models have the advantage. But what about people who only have a hundred GPUs to do? Rich people can choose to spend more cash on medical providers with a purpose to receive better care. Actually, the health care programs in lots of countries are designed to make sure that all persons are treated equally for medical care, regardless of their earnings. So simply because an individual is willing to pay increased premiums, doesn’t imply they deserve higher care. Based on these information, I agree that a rich person is entitled to higher medical providers if they pay a premium for them.
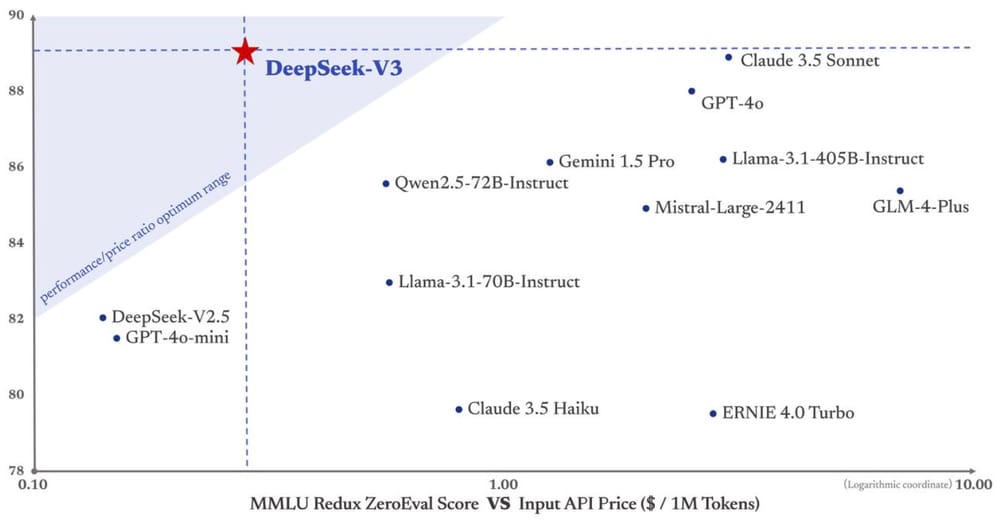
In conclusion, the details assist the idea that a rich individual is entitled to higher medical providers if he or she pays a premium for them, as that is a typical characteristic of market-based mostly healthcare systems and is in line with the precept of particular person property rights and consumer selection. USV-based Panoptic Segmentation Challenge: "The panoptic problem calls for a extra effective-grained parsing of USV scenes, together with segmentation and classification of particular person obstacle situations. Step 2: Parsing the dependencies of recordsdata inside the same repository to rearrange the file positions primarily based on their dependencies. Made in China can be a factor for AI models, identical as electric cars, drones, and different technologies… We launch the deepseek [simply click the following site] LLM 7B/67B, including both base and chat models, to the general public. At the end of 2021, High-Flyer put out a public statement on WeChat apologizing for its losses in belongings as a consequence of poor performance. Mathematical: Performance on the MATH-500 benchmark has improved from 74.8% to 82.8% . In accordance with DeepSeek’s internal benchmark testing, DeepSeek V3 outperforms both downloadable, overtly available models like Meta’s Llama and "closed" fashions that can only be accessed via an API, like OpenAI’s GPT-4o.
댓글목록
등록된 댓글이 없습니다.