How Did We Get There? The Historical past Of Deepseek Instructed By wa…
페이지 정보
작성자 Luther 작성일25-01-31 22:11 조회4회 댓글0건관련링크
본문
DeepSeek LLM series (together with Base and Chat) supports industrial use. Trained meticulously from scratch on an expansive dataset of 2 trillion tokens in both English and Chinese, the DeepSeek LLM has set new standards for research collaboration by open-sourcing its 7B/67B Base and 7B/67B Chat variations. DeepSeek-Coder-V2 is additional pre-skilled from DeepSeek-Coder-V2-Base with 6 trillion tokens sourced from a high-quality and multi-supply corpus. High throughput: DeepSeek V2 achieves a throughput that is 5.76 instances higher than DeepSeek 67B. So it’s able to producing text at over 50,000 tokens per second on commonplace hardware. It’s fascinating how they upgraded the Mixture-of-Experts architecture and a focus mechanisms to new variations, making LLMs more versatile, cost-efficient, and capable of addressing computational challenges, handling long contexts, and dealing very quickly. Multi-Head Latent Attention (MLA): In a Transformer, consideration mechanisms assist the model focus on essentially the most related elements of the enter. This reduces redundancy, making certain that different consultants focus on distinctive, specialised areas. You want folks that are hardware specialists to truly run these clusters. They handle common data that multiple duties may want. By having shared specialists, the mannequin does not must store the identical data in a number of locations. The rule-based reward model was manually programmed.
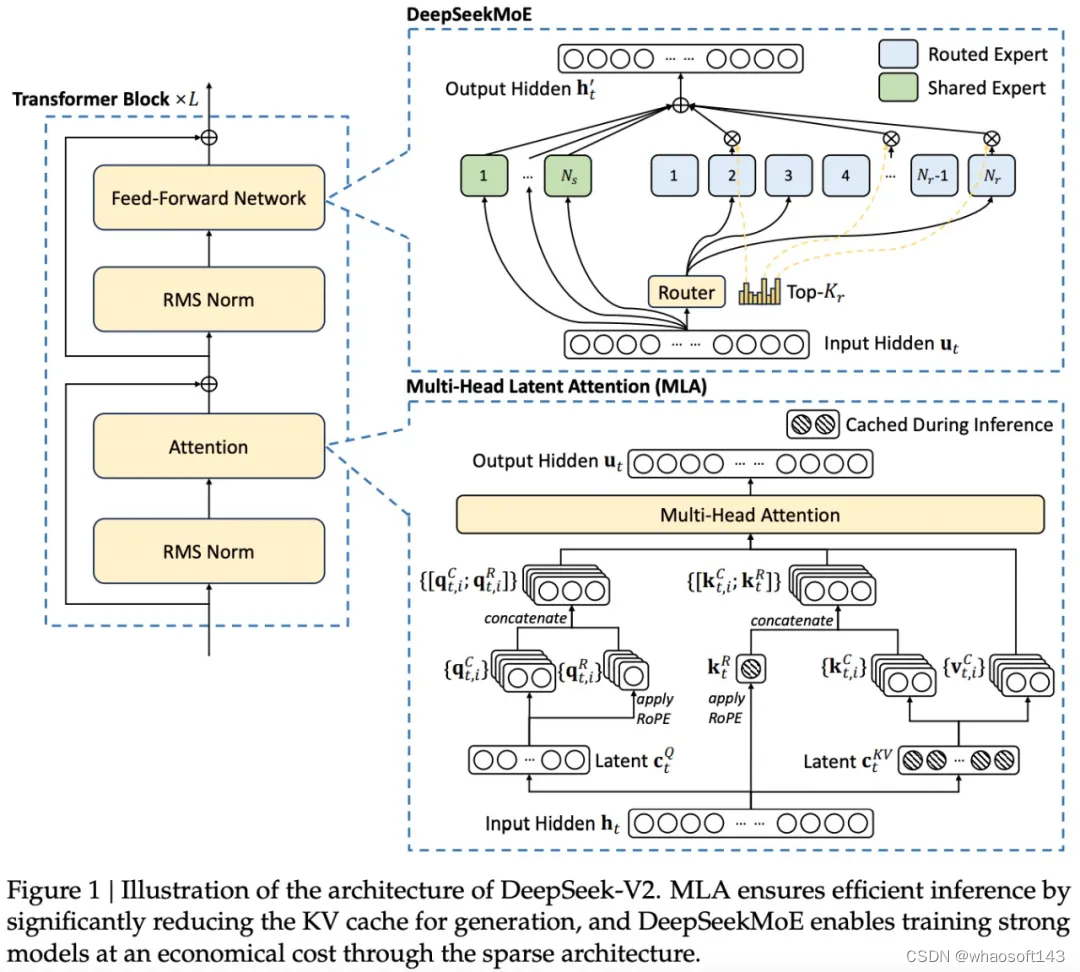 Reinforcement Learning: The model makes use of a more sophisticated reinforcement learning approach, including Group Relative Policy Optimization (GRPO), which makes use of suggestions from compilers and take a look at instances, and deepseek a realized reward model to tremendous-tune the Coder. Model quantization enables one to reduce the reminiscence footprint, and improve inference pace - with a tradeoff towards the accuracy. This enables the mannequin to course of data sooner and with less memory with out shedding accuracy. Fill-In-The-Middle (FIM): One of many special features of this mannequin is its capability to fill in missing parts of code. Fine-grained professional segmentation: DeepSeekMoE breaks down every knowledgeable into smaller, more centered components. Systems like BioPlanner illustrate how AI methods can contribute to the straightforward elements of science, holding the potential to hurry up scientific discovery as a complete. Negative sentiment concerning the CEO’s political affiliations had the potential to result in a decline in gross sales, so DeepSeek launched an internet intelligence program to gather intel that would help the corporate fight these sentiments. GPT-2, while fairly early, confirmed early indicators of potential in code generation and developer productiveness enchancment. Risk of losing data whereas compressing information in MLA.
Reinforcement Learning: The model makes use of a more sophisticated reinforcement learning approach, including Group Relative Policy Optimization (GRPO), which makes use of suggestions from compilers and take a look at instances, and deepseek a realized reward model to tremendous-tune the Coder. Model quantization enables one to reduce the reminiscence footprint, and improve inference pace - with a tradeoff towards the accuracy. This enables the mannequin to course of data sooner and with less memory with out shedding accuracy. Fill-In-The-Middle (FIM): One of many special features of this mannequin is its capability to fill in missing parts of code. Fine-grained professional segmentation: DeepSeekMoE breaks down every knowledgeable into smaller, more centered components. Systems like BioPlanner illustrate how AI methods can contribute to the straightforward elements of science, holding the potential to hurry up scientific discovery as a complete. Negative sentiment concerning the CEO’s political affiliations had the potential to result in a decline in gross sales, so DeepSeek launched an internet intelligence program to gather intel that would help the corporate fight these sentiments. GPT-2, while fairly early, confirmed early indicators of potential in code generation and developer productiveness enchancment. Risk of losing data whereas compressing information in MLA.
This method permits fashions to handle completely different points of information more effectively, improving efficiency and scalability in massive-scale tasks. This permits you to check out many models shortly and effectively for many use cases, resembling DeepSeek Math (mannequin card) for math-heavy duties and Llama Guard (mannequin card) for moderation tasks. This model achieves state-of-the-art efficiency on a number of programming languages and benchmarks. The efficiency of DeepSeek-Coder-V2 on math and code benchmarks. But then they pivoted to tackling challenges as a substitute of simply beating benchmarks. Their initial try and beat the benchmarks led them to create models that were fairly mundane, just like many others. That call was actually fruitful, and now the open-supply family of fashions, including deepseek ai china Coder, DeepSeek LLM, DeepSeekMoE, DeepSeek-Coder-V1.5, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, and DeepSeek-Prover-V1.5, will be utilized for many functions and is democratizing the usage of generative models. Sparse computation attributable to utilization of MoE. Sophisticated architecture with Transformers, MoE and MLA. Faster inference due to MLA. DeepSeek-V2 introduces Multi-Head Latent Attention (MLA), a modified consideration mechanism that compresses the KV cache into a a lot smaller form. KV cache throughout inference, thus boosting the inference efficiency". The newest model, DeepSeek-V2, has undergone important optimizations in structure and efficiency, with a 42.5% discount in coaching costs and a 93.3% reduction in inference costs.
DeepSeek-V3 achieves a major breakthrough in inference speed over previous models. Start Now. free deepseek entry to DeepSeek-V3. Share this article with three pals and get a 1-month subscription free! OpenAI CEO Sam Altman has acknowledged that it price more than $100m to train its chatbot GPT-4, whereas analysts have estimated that the model used as many as 25,000 more superior H100 GPUs. In brief, while upholding the management of the Party, China can be constantly promoting comprehensive rule of regulation and striving to build a more just, equitable, and open social setting. DeepSeek's founder, Liang Wenfeng has been in comparison with Open AI CEO Sam Altman, with CNN calling him the Sam Altman of China and an evangelist for A.I. State-of-the-Art efficiency amongst open code models. To be able to foster analysis, we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open supply for the analysis community. The application permits you to chat with the mannequin on the command line.
If you have any queries about where and also the best way to make use of ديب سيك, you'll be able to e-mail us at our web page.
댓글목록
등록된 댓글이 없습니다.