Are You Struggling With Deepseek? Let's Chat
페이지 정보
작성자 Hildred 작성일25-01-31 23:49 조회10회 댓글0건관련링크
본문
DeepSeek LLM 7B/67B fashions, including base and chat variations, are launched to the public on GitHub, Hugging Face and likewise AWS S3. Whereas, the GPU poors are usually pursuing extra incremental modifications primarily based on techniques which might be identified to work, that may enhance the state-of-the-artwork open-supply models a moderate amount. That is exemplified of their DeepSeek-V2 and free deepseek-Coder-V2 fashions, with the latter widely thought to be one of the strongest open-supply code fashions out there. DeepSeek-Coder-V2 is an open-source Mixture-of-Experts (MoE) code language mannequin that achieves efficiency comparable to GPT4-Turbo in code-specific duties. Code Llama is specialized for code-specific duties and isn’t appropriate as a basis mannequin for other tasks. We introduce a system prompt (see below) to guide the mannequin to generate answers within specified guardrails, similar to the work performed with Llama 2. The prompt: "Always assist with care, respect, and truth. China has already fallen off from the peak of $14.Four billion in 2018 to $1.Three billion in 2022. More work also must be achieved to estimate the extent of anticipated backfilling from Chinese domestic and non-U.S. Jordan Schneider: One of many ways I’ve thought about conceptualizing the Chinese predicament - possibly not in the present day, but in maybe 2026/2027 - is a nation of GPU poors.
 In addition, by triangulating various notifications, this system may determine "stealth" technological developments in China which will have slipped under the radar and serve as a tripwire for potentially problematic Chinese transactions into the United States underneath the Committee on Foreign Investment in the United States (CFIUS), which screens inbound investments for nationwide security dangers. The 2 subsidiaries have over 450 investment merchandise. However, relying on cloud-based services typically comes with issues over information privateness and safety. The limited computational sources-P100 and T4 GPUs, each over five years outdated and much slower than extra superior hardware-posed a further challenge. By harnessing the suggestions from the proof assistant and utilizing reinforcement studying and Monte-Carlo Tree Search, DeepSeek-Prover-V1.5 is able to learn how to unravel complex mathematical problems more successfully. Reinforcement studying is a sort of machine learning the place an agent learns by interacting with an environment and receiving suggestions on its actions. Interpretability: As with many machine studying-primarily based programs, the inside workings of DeepSeek-Prover-V1.5 is probably not fully interpretable. DeepSeek-Prover-V1.5 is a system that combines reinforcement learning and Monte-Carlo Tree Search to harness the suggestions from proof assistants for improved theorem proving. This innovative method has the potential to significantly accelerate progress in fields that rely on theorem proving, similar to mathematics, computer science, and beyond.
In addition, by triangulating various notifications, this system may determine "stealth" technological developments in China which will have slipped under the radar and serve as a tripwire for potentially problematic Chinese transactions into the United States underneath the Committee on Foreign Investment in the United States (CFIUS), which screens inbound investments for nationwide security dangers. The 2 subsidiaries have over 450 investment merchandise. However, relying on cloud-based services typically comes with issues over information privateness and safety. The limited computational sources-P100 and T4 GPUs, each over five years outdated and much slower than extra superior hardware-posed a further challenge. By harnessing the suggestions from the proof assistant and utilizing reinforcement studying and Monte-Carlo Tree Search, DeepSeek-Prover-V1.5 is able to learn how to unravel complex mathematical problems more successfully. Reinforcement studying is a sort of machine learning the place an agent learns by interacting with an environment and receiving suggestions on its actions. Interpretability: As with many machine studying-primarily based programs, the inside workings of DeepSeek-Prover-V1.5 is probably not fully interpretable. DeepSeek-Prover-V1.5 is a system that combines reinforcement learning and Monte-Carlo Tree Search to harness the suggestions from proof assistants for improved theorem proving. This innovative method has the potential to significantly accelerate progress in fields that rely on theorem proving, similar to mathematics, computer science, and beyond.
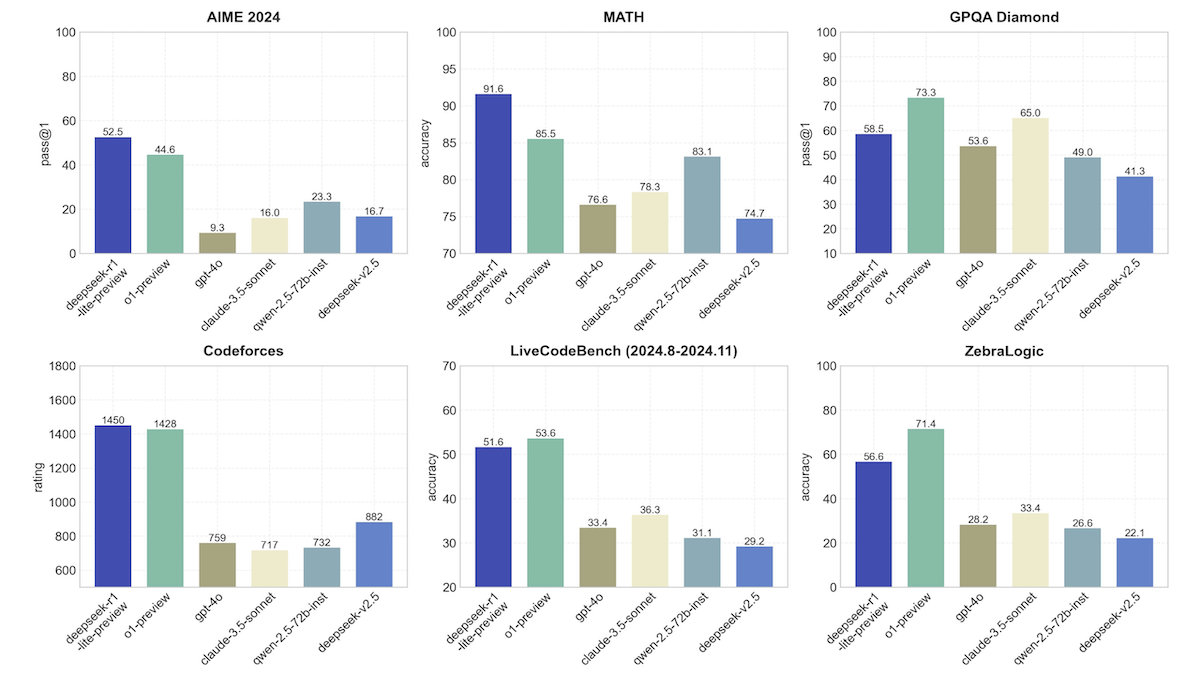 The key contributions of the paper embody a novel strategy to leveraging proof assistant feedback and advancements in reinforcement studying and search algorithms for theorem proving. Overall, the DeepSeek-Prover-V1.5 paper presents a promising approach to leveraging proof assistant suggestions for improved theorem proving, and the outcomes are impressive. And what about if you’re the subject of export controls and are having a hard time getting frontier compute (e.g, if you’re DeepSeek). Each of these developments in DeepSeek V3 may very well be lined in short weblog posts of their own. DeepSeek Chat has two variants of 7B and 67B parameters, that are skilled on a dataset of 2 trillion tokens, says the maker. Are there any specific options that could be beneficial? And then there are some positive-tuned information sets, whether it’s synthetic information units or information units that you’ve collected from some proprietary source somewhere. As such, there already seems to be a brand new open source AI model chief simply days after the last one was claimed.
The key contributions of the paper embody a novel strategy to leveraging proof assistant feedback and advancements in reinforcement studying and search algorithms for theorem proving. Overall, the DeepSeek-Prover-V1.5 paper presents a promising approach to leveraging proof assistant suggestions for improved theorem proving, and the outcomes are impressive. And what about if you’re the subject of export controls and are having a hard time getting frontier compute (e.g, if you’re DeepSeek). Each of these developments in DeepSeek V3 may very well be lined in short weblog posts of their own. DeepSeek Chat has two variants of 7B and 67B parameters, that are skilled on a dataset of 2 trillion tokens, says the maker. Are there any specific options that could be beneficial? And then there are some positive-tuned information sets, whether it’s synthetic information units or information units that you’ve collected from some proprietary source somewhere. As such, there already seems to be a brand new open source AI model chief simply days after the last one was claimed.
The paper introduces DeepSeekMath 7B, a large language mannequin educated on a vast quantity of math-related knowledge to enhance its mathematical reasoning capabilities. The paper introduces DeepSeekMath 7B, a large language mannequin that has been pre-trained on a massive amount of math-related information from Common Crawl, totaling one hundred twenty billion tokens. A standard use case in Developer Tools is to autocomplete based mostly on context. First, they gathered a large quantity of math-associated knowledge from the web, together with 120B math-associated tokens from Common Crawl. Synthesize 200K non-reasoning information (writing, factual QA, self-cognition, translation) utilizing free deepseek-V3. Monte-Carlo Tree Search, alternatively, is a approach of exploring potential sequences of actions (in this case, logical steps) by simulating many random "play-outs" and utilizing the results to information the search in the direction of extra promising paths. I retried a pair more times. Scalability: The paper focuses on comparatively small-scale mathematical problems, and it is unclear how the system would scale to bigger, more complicated theorems or proofs.
If you have almost any issues relating to where and also the best way to utilize ديب سيك, you are able to call us with the web site.
댓글목록
등록된 댓글이 없습니다.