Thirteen Hidden Open-Supply Libraries to Change into an AI Wizard
페이지 정보
작성자 Titus Britt 작성일25-02-01 00:36 조회17회 댓글0건관련링크
본문
 DeepSeek stated it will release R1 as open supply however didn't announce licensing terms or a release date. We launch the free deepseek LLM 7B/67B, including both base and chat models, to the general public. The recent launch of Llama 3.1 was paying homage to many releases this year. Advanced Code Completion Capabilities: A window dimension of 16K and a fill-in-the-blank process, supporting challenge-stage code completion and infilling duties. Although the deepseek-coder-instruct models aren't particularly skilled for code completion duties throughout supervised advantageous-tuning (SFT), they retain the capability to perform code completion successfully. This modification prompts the model to acknowledge the end of a sequence in a different way, thereby facilitating code completion duties. Alibaba’s Qwen model is the world’s finest open weight code mannequin (Import AI 392) - and they achieved this by way of a combination of algorithmic insights and entry to knowledge (5.5 trillion prime quality code/math ones). It aims to improve total corpus high quality and remove dangerous or toxic content material.
DeepSeek stated it will release R1 as open supply however didn't announce licensing terms or a release date. We launch the free deepseek LLM 7B/67B, including both base and chat models, to the general public. The recent launch of Llama 3.1 was paying homage to many releases this year. Advanced Code Completion Capabilities: A window dimension of 16K and a fill-in-the-blank process, supporting challenge-stage code completion and infilling duties. Although the deepseek-coder-instruct models aren't particularly skilled for code completion duties throughout supervised advantageous-tuning (SFT), they retain the capability to perform code completion successfully. This modification prompts the model to acknowledge the end of a sequence in a different way, thereby facilitating code completion duties. Alibaba’s Qwen model is the world’s finest open weight code mannequin (Import AI 392) - and they achieved this by way of a combination of algorithmic insights and entry to knowledge (5.5 trillion prime quality code/math ones). It aims to improve total corpus high quality and remove dangerous or toxic content material.
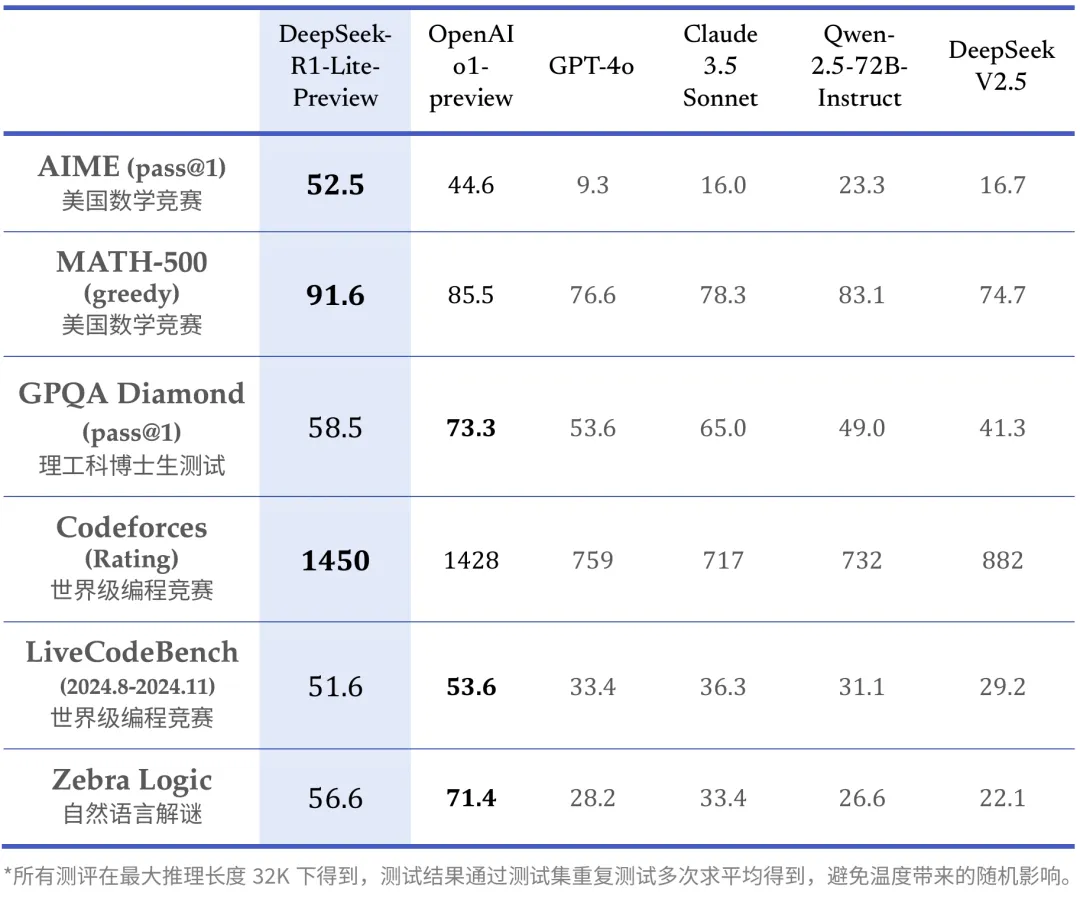
 Please notice that using this mannequin is subject to the phrases outlined in License part. The usage of DeepSeek LLM Base/Chat models is subject to the Model License. NOT paid to use. Some experts worry that the government of China may use the A.I. They proposed the shared specialists to study core capacities that are often used, and let the routed consultants to study the peripheral capacities which are hardly ever used. Both a `chat` and `base` variation can be found. This exam comprises 33 problems, and the mannequin's scores are decided by way of human annotation. How it works: DeepSeek-R1-lite-preview makes use of a smaller base model than DeepSeek 2.5, which contains 236 billion parameters. Superior General Capabilities: DeepSeek LLM 67B Base outperforms Llama2 70B Base in areas similar to reasoning, coding, math, and Chinese comprehension. How lengthy till some of these methods described right here present up on low-value platforms either in theatres of great energy conflict, or in asymmetric warfare areas like hotspots for maritime piracy?
Please notice that using this mannequin is subject to the phrases outlined in License part. The usage of DeepSeek LLM Base/Chat models is subject to the Model License. NOT paid to use. Some experts worry that the government of China may use the A.I. They proposed the shared specialists to study core capacities that are often used, and let the routed consultants to study the peripheral capacities which are hardly ever used. Both a `chat` and `base` variation can be found. This exam comprises 33 problems, and the mannequin's scores are decided by way of human annotation. How it works: DeepSeek-R1-lite-preview makes use of a smaller base model than DeepSeek 2.5, which contains 236 billion parameters. Superior General Capabilities: DeepSeek LLM 67B Base outperforms Llama2 70B Base in areas similar to reasoning, coding, math, and Chinese comprehension. How lengthy till some of these methods described right here present up on low-value platforms either in theatres of great energy conflict, or in asymmetric warfare areas like hotspots for maritime piracy?
They’re also higher on an vitality standpoint, generating much less heat, making them simpler to power and integrate densely in a datacenter. Can LLM's produce better code? For instance, the artificial nature of the API updates might not absolutely seize the complexities of actual-world code library adjustments. This makes the mannequin more transparent, however it might also make it extra susceptible to jailbreaks and different manipulation. On AIME math issues, performance rises from 21 % accuracy when it makes use of less than 1,000 tokens to 66.7 percent accuracy when it makes use of greater than 100,000, surpassing o1-preview’s performance. More results could be found within the evaluation folder. Here, we used the primary model launched by Google for the analysis. For the Google revised test set analysis outcomes, please seek advice from the number in our paper. It is a Plain English Papers abstract of a research paper called DeepSeekMath: Pushing the bounds of Mathematical Reasoning in Open Language Models. Having these massive fashions is good, however very few fundamental points could be solved with this. How it works: "AutoRT leverages imaginative and prescient-language fashions (VLMs) for scene understanding and grounding, and additional makes use of giant language fashions (LLMs) for proposing various and novel instructions to be carried out by a fleet of robots," the authors write.
The topic started because somebody requested whether or not he still codes - now that he's a founder of such a big company. Now the apparent question that will are available in our mind is Why ought to we know about the newest LLM developments. Now we set up and configure the NVIDIA Container Toolkit by following these instructions. Nvidia literally misplaced a valuation equal to that of your entire Exxon/Mobile corporation in one day. He saw the sport from the attitude of one in all its constituent parts and was unable to see the face of whatever giant was moving him. This is one of those things which is both a tech demo and likewise an important sign of things to come back - sooner or later, we’re going to bottle up many different parts of the world into representations realized by a neural web, then permit these things to come back alive inside neural nets for countless era and recycling. DeepSeek-Coder and DeepSeek-Math have been used to generate 20K code-related and 30K math-related instruction knowledge, then combined with an instruction dataset of 300M tokens. We pre-trained deepseek ai language fashions on an unlimited dataset of two trillion tokens, with a sequence size of 4096 and AdamW optimizer.
When you adored this post as well as you want to obtain more information relating to ديب سيك مجانا i implore you to visit our webpage.
댓글목록
등록된 댓글이 없습니다.